
Client
The client can run as a user-space executable program in a container and provide the mounted volume and file system interfaces to other user-space applications through FUSE.
Client Cache
The client process will use the client cache in the following situations:
- In order to reduce the communication burden with the resource management node, the client will obtain the addresses of all metadata and data nodes in the mounted volume during the mount startup and cache them. The cache will be updated periodically from the resource management node.
- In order to reduce communication with the metadata node, the client caches inode, dentry, and extent metadata information. In general, read requests should be able to read all previous writes, but the client metadata cache may cause consistency issues when multiple clients write to the same file. Therefore, in the design of CubeFS, different clients or mount points can read a file at the same time, but cannot write to the same file at the same time. When opening a file, the client will force the file metadata information to be updated from the metadata node.
Note
Different processes can concurrently write to a file from the same mount point, but the issue of data concurrency needs to be resolved to prevent data corruption.
During fault recovery, the leader node of the Raft replication group may change, causing the cached address of the client to be invalid. Therefore, when the client receives a "not leader" reply after sending a request, it will retry all nodes in the replication group. After a successful retry, the new leader node will be identified, and the client will cache the address of the new leader node.
Integration with FUSE Interface
The CubeFS client integrates with FUSE to provide user-space file system interfaces.
Note
Previously, low performance was considered the biggest disadvantage of user-space file systems. However, after years of development, FUSE has made significant improvements in performance. In the future, CubeFS will develop a kernel-space file system client.
Currently, the writeback cache feature of FUSE has not achieved the expected performance improvement.
The default write process of FUSE uses the directIO interface, which causes performance issues when the write length is small because each write request is pushed to the backend storage.
FUSE's solution is the writeback cache, which means that small writes are written to the cache page and returned, and the kernel pushes them to the backend storage based on the flushing policy. In this way, sequential small requests can be aggregated.
However, in actual production, we found that the writeback cache feature is very limited in its effectiveness. The reason is that the write operation that uses the write cache triggers the kernel's balance dirty page process, causing the write operation, which should have a very short response time, to still wait for a long time to return, especially when the write length is small.
Live Upgrade
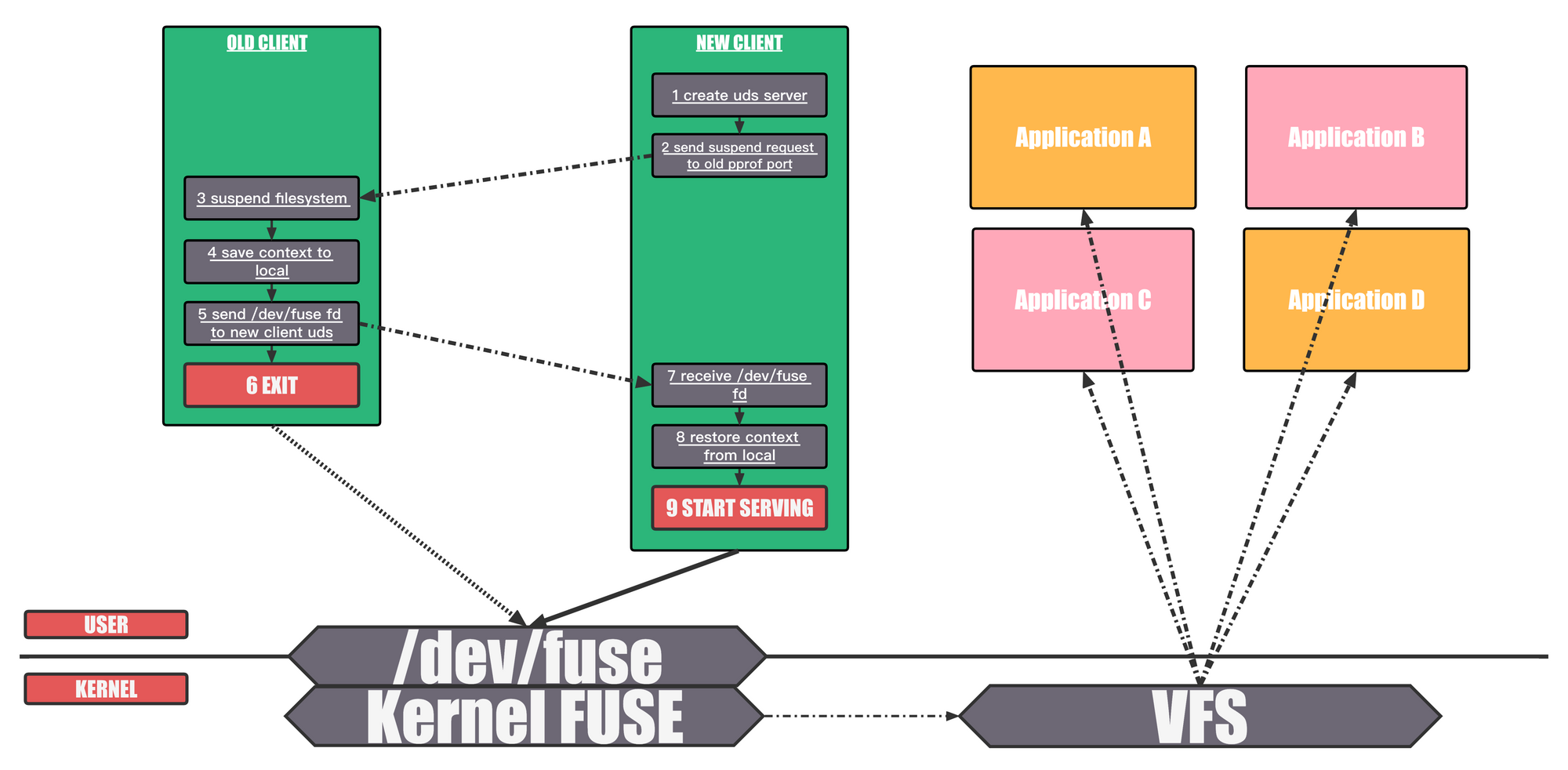
Online live upgrade,while the old client is still running, the new client will communicate with it to take over the control of all fuse requests.
Allows to upgrade fuse client without umounting. The following stes are executed to achieve that:
stop reading more requests from /dev/fuse
save context
Context saves information of inodes/files, which are still in use (open or not evicted) between fuse client and fuse kernel module.
save file descriptor of /dev/fuse
Use Unix Domain Socket to transmit fd.
old client exits and new client starts
restore context
New client tries to restore context instead of really mounting fuse.
restore file descriptor of /dev/fuse
New client keep reading pending requests.
Client Warm-up
To improve the read efficiency of the erasure-coded volume, the client can cache the data of the erasure-coded subsystem to the replica subsystem through the warm-up function. The cached content in the replica subsystem will be automatically deleted after the warm-up TTL expires.
Level 1 Cache (Data Cache)
L1Cache is a local data cache service independent of the client, which provides Put/Get/Delete interfaces to cache read/write and eviction operations based on data blocks (Blocks). The overall structure is shown in the following figure.
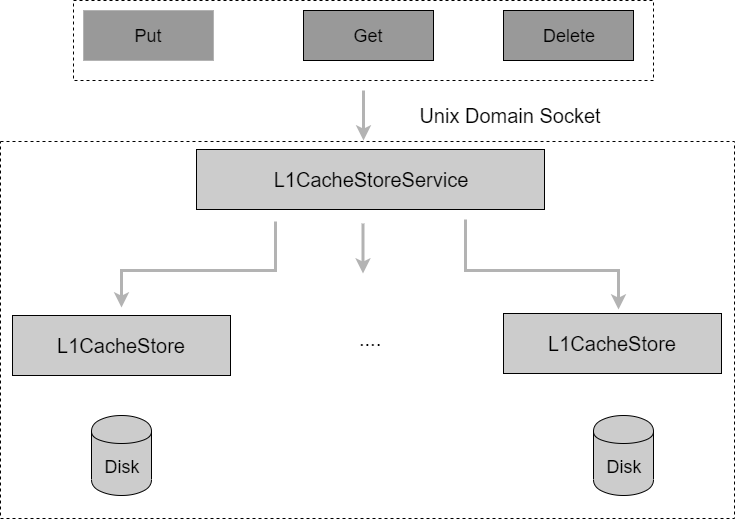
The L1Cache caching service provides caching services to all clients that have configured Level 1 caching.
The local cached data blocks correspond one-to-one with the remote storage data blocks and are accessed by block indexing (BlockKey). The data block index BlockKey is generated as follows: VolumeName_Inode_hex(FileOffset).
Note
The data block index is mapped to the local cache file structure through two modulo calculations, LocalPath / hash(BlockKey)%512 / hash(BlockKey)%256 / BlockKey.
The L1CacheStoreService uniformly maintains global BlockKeys and periodically evicts them based on LRU.
When the L1Cache service is restarted, it automatically scans the cached data on the disk and rebuilds the cache index information. The addition and exit of the cache directory does not involve data migration. Lost cache data is re-cached, and residual cache data will eventually be evicted by LRU.