
可视化配置
Grafana配置模板
提示
当前纠删码子系统的监控指标模板还未包含在对应配置模块示例中,后续完善
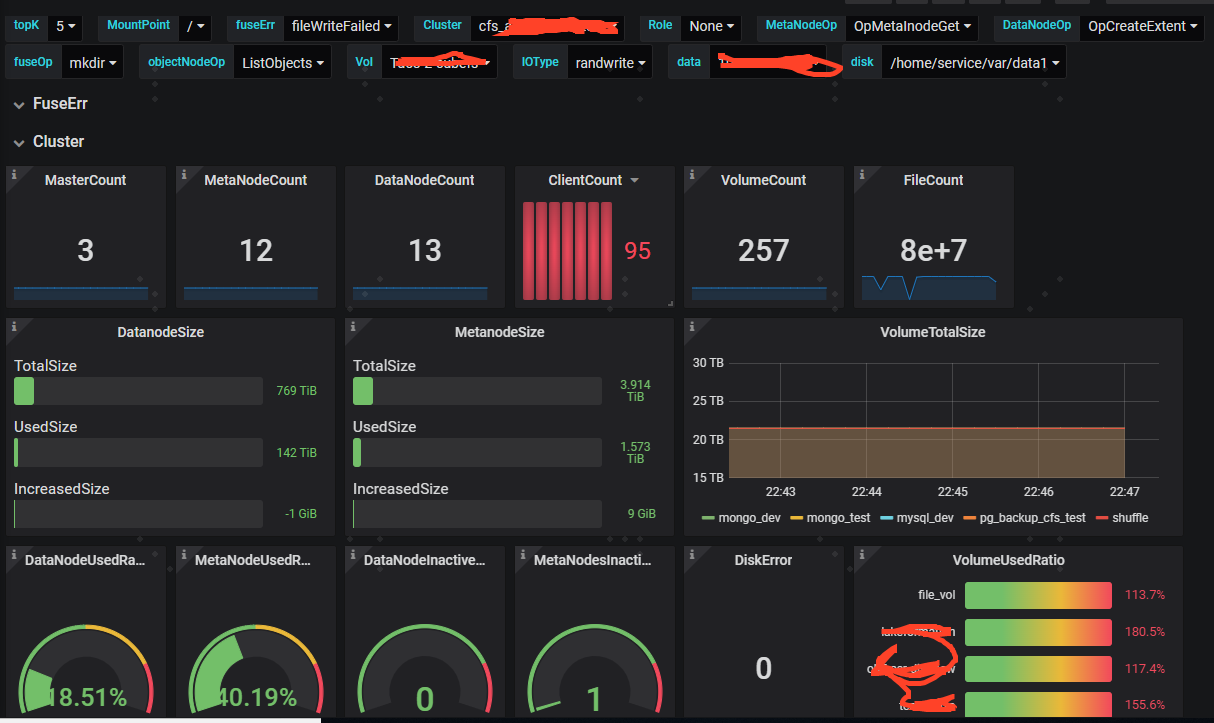
- 可以通过grafana来展示监控数据,如下图
- 配置模板参考docker/monitor/grafana/provisioning/dashboards/*.json文件
- 可通过prometheus alertmanager配置监控告警能力,参考alertmanager文档
- 相关参考
纠删码子系统指标
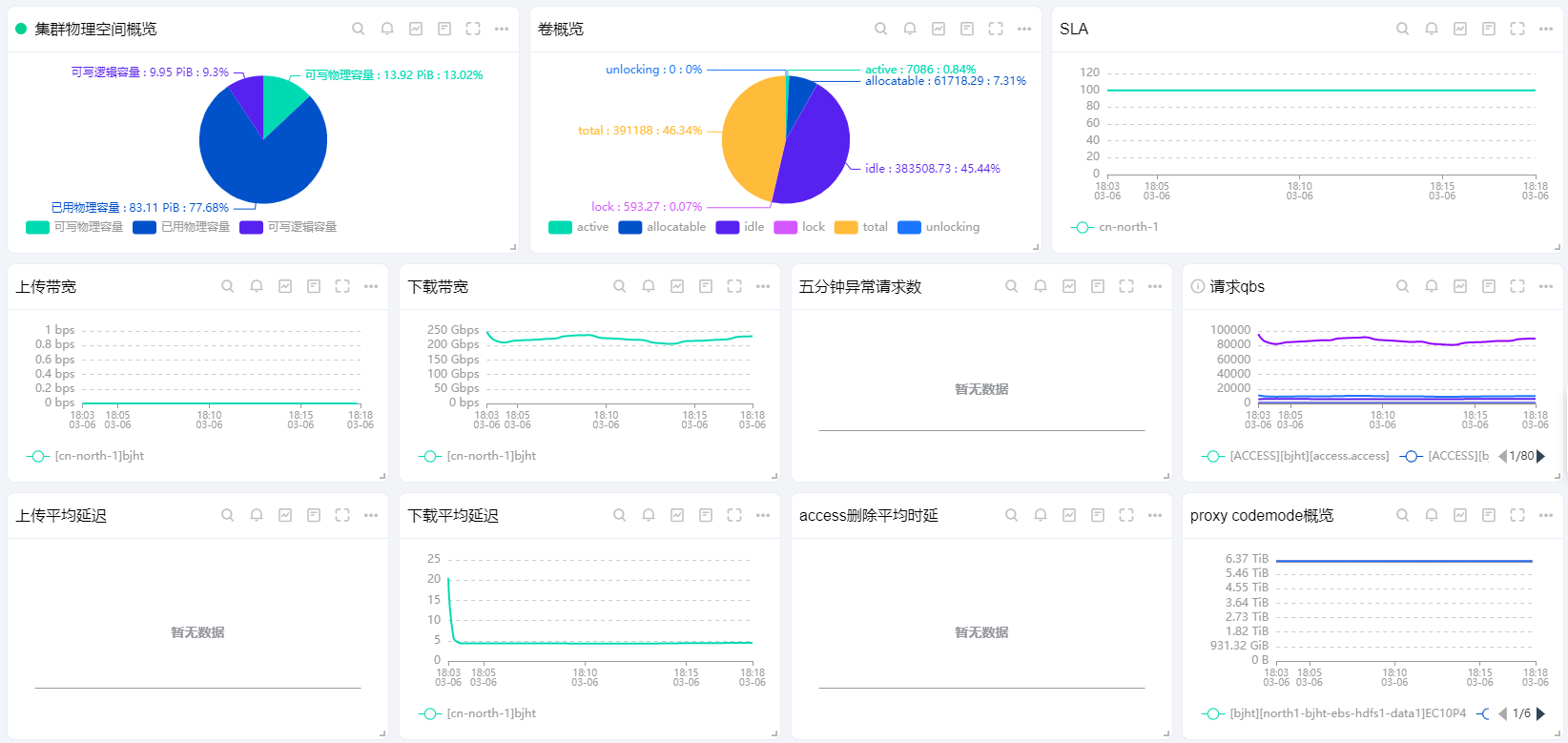
可以结合前面介绍的监控指标项配置个性化的监控面板,如以下面板示例。
提示
- 替换
cluster/cluster_id为集群id service标签为服务名字,在审计日志指标配置项配置
集群物理空间概览
# 可写物理容量
# 单位 bytes
sum by (item)(blobstore_clusterMgr_space_stat_info{cluster="${cluster_id}",item="FreeSpace",is_leader="true"})
# 已用物理容量
# 单位 bytes
sum by (item)(blobstore_clusterMgr_space_stat_info{cluster="${cluster_id}",item="UsedSpace",is_leader="true"})
# 可写逻辑容量
# 单位 bytes
sum by (item)(blobstore_clusterMgr_space_stat_info{cluster="${cluster_id}1",item="UsedSpace",is_leader="true"})
卷概览
# 单位 个数
sum by (status) (blobstore_clusterMgr_vol_status_vol_count{cluster="${cluster_id}",is_leader="true"})
SLA
((sum by (service)(rate(service_response_code{service="ACCESS",code=~"4..|3..|2..|1.."}[5m]))>0)/(sum by (service)(rate(service_response_code{service="ACCESS"}[5m]))>0))*100
上传带宽
# 单位 bits/sec
sum by (idc) (rate(service_request_length{service="ACCESS",api=~"access.put|access.putat"}[5m]))*8
下载带宽
# 单位 bits/sec
sum by (idc) (rate(service_response_length{service="ACCESS",api=~"access.get"}[5m]))*8
五分钟请求异常
# 单位 个数
sum by (api,service,code)(increase(service_response_code{code!~"200|206|404|700|702|621|622|651|654|923"}[5m]))>0
请求qps
# 单位 个数
sum by (service,idc,api)(rate(service_response_code{}[5m]))
上传平均时延
# 单位 ms
(histogram_quantile(0.95, sum by(idc,le) (rate(service_response_duration_ms_bucket{code=~"2..",service="ACCESS",api=~"access.put|access.putat"}[5m]))))>0
下载平均时延
# 单位 ms
(histogram_quantile(0.95, sum by(idc,le) (rate(service_response_duration_ms_bucket{code=~"2..",service="ACCESS",api=~"access.get"}[5m]))))>0
删除平均时延
# 单位 ms
histogram_quantile(0.95, sum by(idc,le) (rate(service_response_duration_ms_bucket{code=~"2..",service="ACCESS",api="access.delete"}[5m])))>0
proxy codemode概览
# 单位 个数
sum by(idc,codemode) (blobstore_proxy_volume_status{cluster="${cluster_id}",type="total_free_size"})
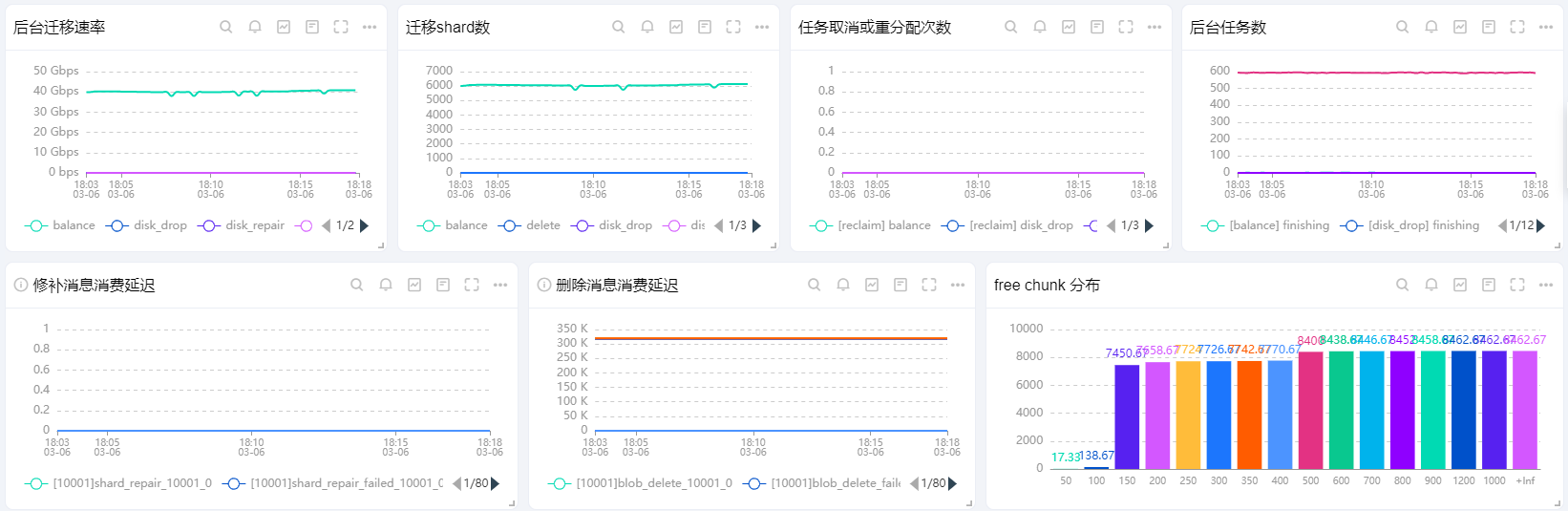
后台迁移速率
# 单位 bits/sec
sum by (task_type) (rate(scheduler_task_data_size{cluster_id="${cluster_id}"}[5m]))*8
迁移shard数
# 单位 个数
sum by (task_type) (rate(scheduler_task_shard_cnt{cluster_id="${cluster_id}"}[5m]))
任务取消或重分配次数
# 单位 个数
sum (increase(scheduler_task_reclaim{cluster_id="${cluster_id}"}[5m])) by (task_type)
sum (increase(scheduler_task_cancel{cluster_id="${cluster_id}"}[5m])) by (task_type)
后台任务数
# 单位 个数
sum by (task_type,task_status) (scheduler_task_cnt{cluster_id="${cluster_id}"})
修补消息消费延迟
# 注意这里topic需要替换对应修补消息的主题
min by (cluster_id,topic,partition)(kafka_topic_partition_consume_lag{cluster_id="${cluster_id}",topic=~".*.shard_repair.*|shard.*",module_name="SCHEDULER"})
删除消息消费延迟
# 注意这里topic需要替换对应删除消息的主题
min by (cluster_id,topic,partition)(kafka_topic_partition_consume_lag{cluster_id="${cluster_id}",topic=~"blob_delete.*|.*.blob_delete.*",module_name="SCHEDULER"})
free chunk分布
sum(increase(scheduler_free_chunk_cnt_range_bucket{}[1m])) by(le)>0
在github上编辑