
OPPO数据湖统一存储技术实践

导读
OPPO是一家智能终端制造公司,有着数亿的终端用户,手机 、IoT设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何低成本存储、高效利用是大数据部门必须要解决的问题。目前业界流行的解决方案是数据湖,本次Xiaochun He老师介绍的OPPO自研数据湖存储系统CBFS在很大程度上可解决目前的痛点。本文将从以下几点为大家展开介绍:
简述数据湖存储技术
OPPO数据湖存储CBFS的架构设计
数据湖存储CBFS的关键技术
数据湖存储CBFS的未来展望
数据湖简述
数据湖定义:一种集中化的存储仓库,它将数据按其原始的数据格式存储,通常是二进制blob或者文件。一个数据湖通常是一个单一的数据集,包括原始数据以及转化后的数据(报表,可视化,高级分析和机器学习等)。
数据湖存储的价值
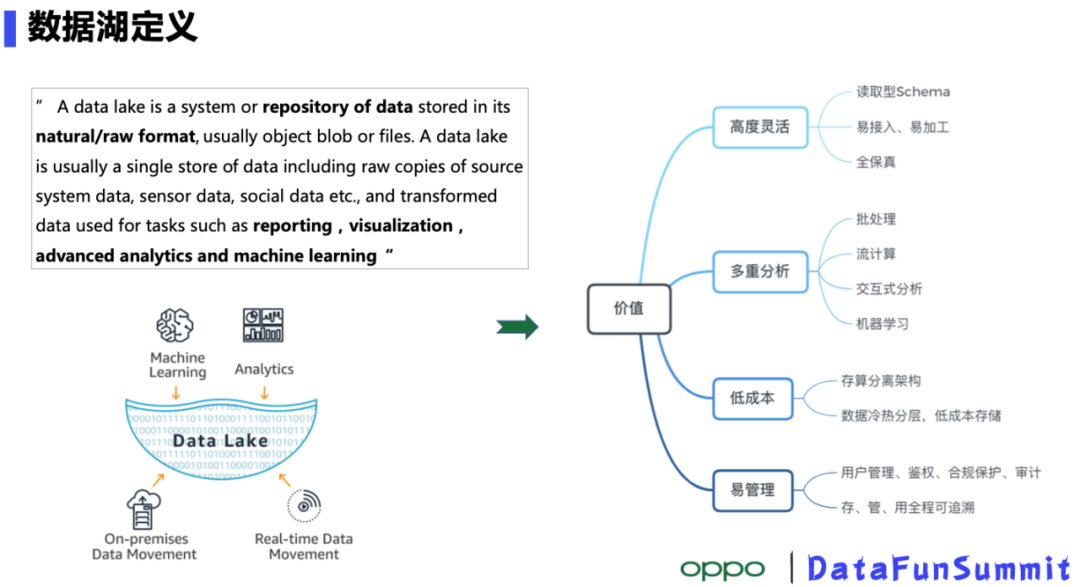 对比传统的Hadoop架构,数据湖有以下几个优点:
对比传统的Hadoop架构,数据湖有以下几个优点:
- 高度灵活:数据的读取、写入和加工都很方便,可保存所有的原始数据
- 多重分析:支持包括批、流计算,交互式查询,机器学习等多种负载
- 低成本:存储计算资源独立扩展;采用对象存储,冷热分离,成本更低
- 易管理:完善的用户管理鉴权,合规和审计,数据“存管用”全程可追溯
OPPO数据湖整体解决方案
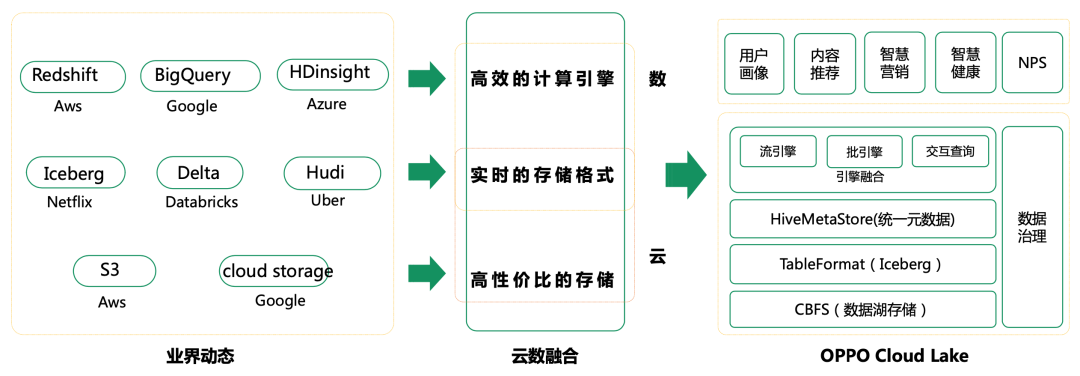
OPPO主要从三个维度建设数据湖:最底层的湖存储,采用的是CBFS,它是一种同时支持S3、HDFS、POSIX文件3种接入协议的低成本存储;中间层是实时数据存储格式,采用了iceberg;最上层可支持各种不同的计算引擎。
OPPO数据湖架构特点
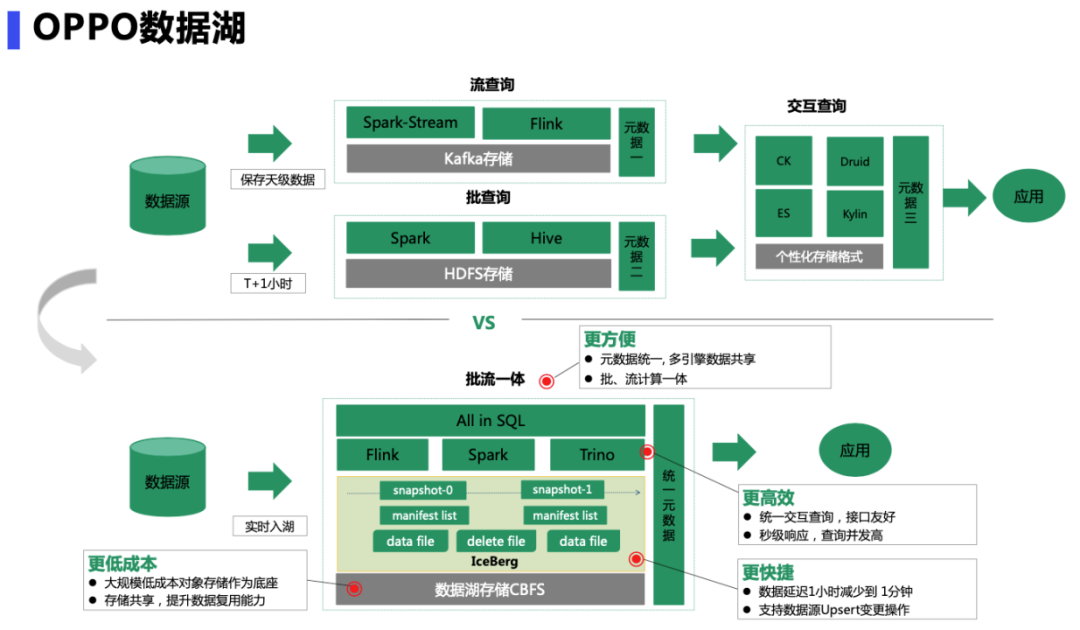 早期大数据存储特点是流计算和批计算的存储放在不同的系统中,升级后的架构统一了的元数据管理,批、流计算一体化;同时提供统一的交互查询,接口更友好,秒级响应,并发度高,同时支持数据源Upsert变更操作;底层采用大规模低成本的对象存储作为统一的数据底座,支持多引擎数据共享,提升数据复用能力
早期大数据存储特点是流计算和批计算的存储放在不同的系统中,升级后的架构统一了的元数据管理,批、流计算一体化;同时提供统一的交互查询,接口更友好,秒级响应,并发度高,同时支持数据源Upsert变更操作;底层采用大规模低成本的对象存储作为统一的数据底座,支持多引擎数据共享,提升数据复用能力
数据湖存储CBFS架构
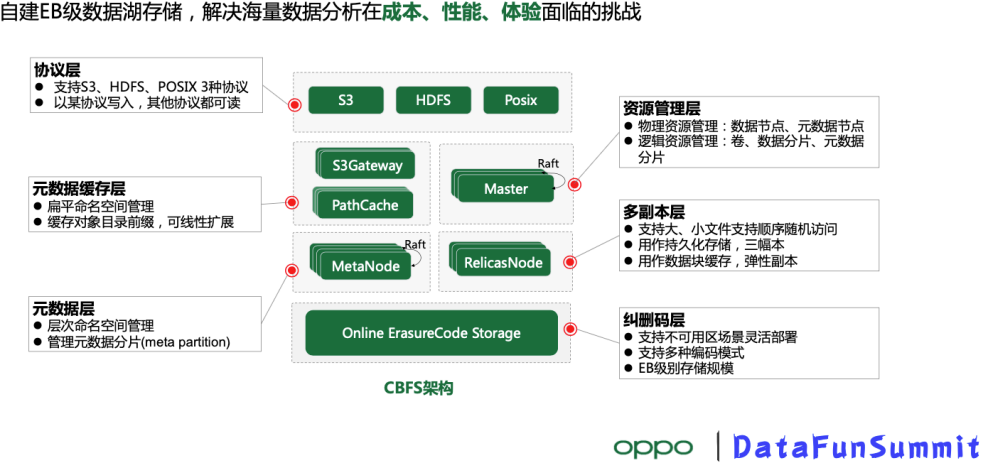
我们的目标是建设可支持EB级数据的数据湖存储,解决数据分析在成本、性能和体验的挑战,整个数据湖存储分成六个子系统:
协议接入层:支持多种不同的协议(S3、HDFS、Posix文件),可做到数据用其中一种协议写入,用另外两种协议也可直接读到
元数据层:对外呈现文件系统的层次命名空间和对象的扁平命名空间,整个元数据是分布式的,支持分片,线性可扩展
元数据缓存层:用来管理元数据缓存,提供元数据访问加速能力
资源管理层:图中的Master节点,负责了物理资源(数据节点,元数据节点)以及逻辑资源(卷/桶,数据分片,元数据分片)的管理
多副本层:支持追加写和随机写,对大对象和小对象都比较友好。该子系统一个作用是作为持久化的多副本存储;另一个作用是数据缓存层,支持弹性副本,加速数据湖访问,后续再展开
纠删码存储层:能显著降低存储成本,同时支持多可用区部署,支持不同的纠删码模型,轻松支持EB级存储规模
接下来,会重点分享下CBFS用到的关键技术,包括高性能的元数据管理、纠删码存储、以及湖加速。
CBFS关键技术
元数据管理
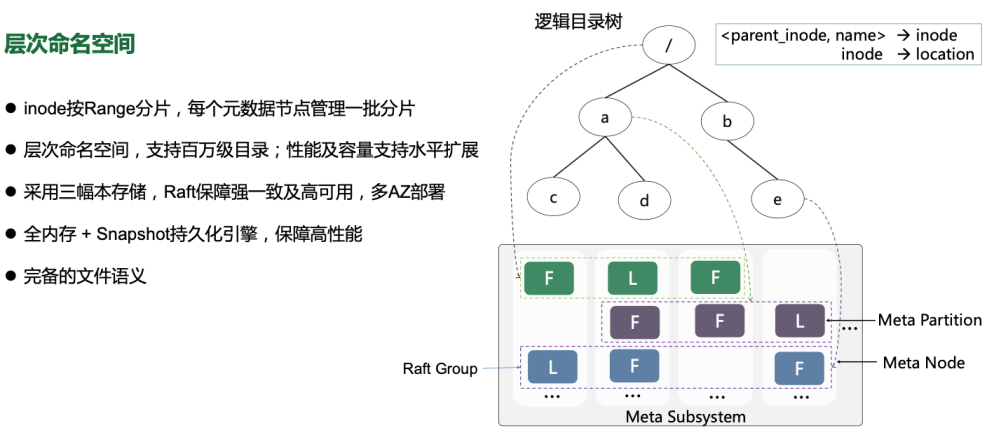
文件系统提供的是层次命名空间视图,整个文件系统的逻辑目录树分成多层,如右图所示,每个元数据节点(MetaNode)包含成百上千的元数据分片(MetaPartition),每个分片由InodeTree(BTree)和DentryTree(BTree)组成,每个dentry代表一个目录项,dentry由parentId和name组成。在DentryTree中,以PartentId和name组成索引,进行存储和检索;在InodeTree中,则以inode id进行索引。使用multiRaft协议保障高可用性和数据一致性复制, 且每个节点集合会包含大量的分片组,每个分片组对应一个raft group;每个分片组隶属于某个volume;每个分片组都是某个volume的一段元数据范围(一段inode id ); 元数据子系统通过分裂来完成动态扩容;当一分片组资源(性能、容量)紧接临近值时,资源管理器服务会预估一个结束点,并通知此组节点设备,只服务到此点之前的数据,同时也会新选出一组节点,并动态加入到当前业务系统中。
单个目录支持百万级别容量,元数据全内存化,保证优秀的读写性能,内存元数据分片通过snapshot方式持久化到磁盘以作备份及恢复使用。
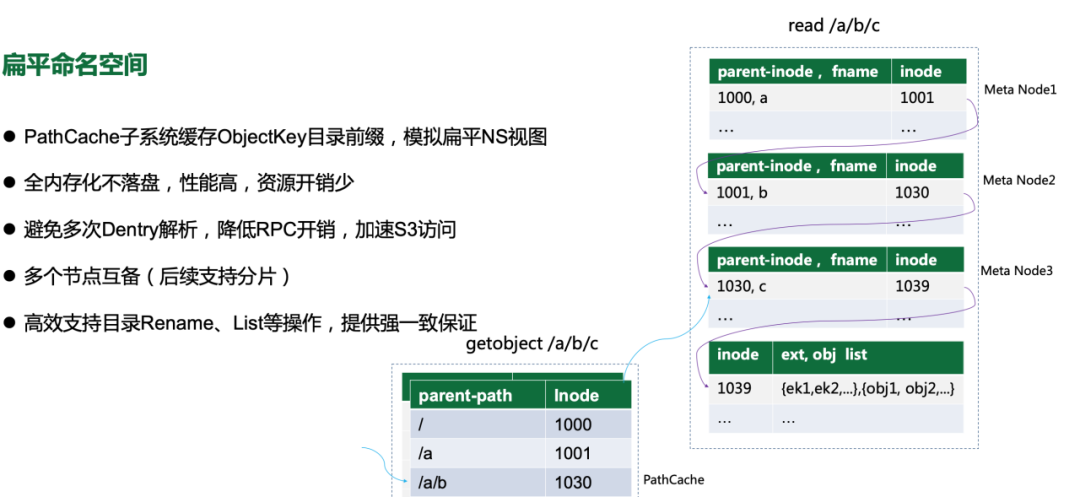
而对象存储提供的是扁平命名空间;以访问objectkey为/bucket/a/b/c的对象为例,从根目录开始,通过”/”分隔符层层解析,找到最后一层目录(/bucket/a/b)的Dentry,最后找到的/bucket/a/b/c对于的Inode,此过程涉及多次节点间交互,层次越深,性能较差;因此我们引入PathCache模块用于加速ObjectKey解析,简单做法是在PathCache中对ObjectKey的父目录(/bucket/a/b)的Dentry做缓存;分析线上集群我们发现,目录平均大小约为100,假设存储集群规模在千亿级别,目录条目也才10亿个,单机缓存效率很高,同时可通过节点扩容来提升读性能;在同时支持"扁平"和"层次"命名空间管理的设计,与业界其他系统相比,CBFS实现得更简洁,更高效,无需任何转换即可轻松实现一份数据,多种协议访问互通,且不存在数据一致性问题。
纠删码存储
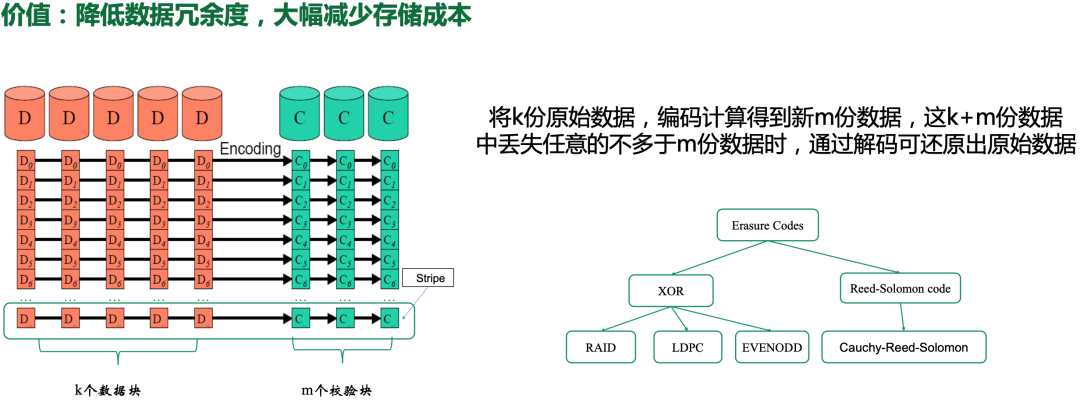
降低存储成本的关键技术之一是纠删码(Erasure Code, 简称EC),简单介绍一下纠删码原理:将k份原始数据,通过编码计算得到新的m份数据,当k+m份数据丢失任意的不多于m份时,通过解码可还原出原始数据(原理有点像磁盘raid);相比传统的多副本存储, EC的数据冗余度更低,但数据耐久性(durability)更高;其实现也有多种不同方式,多数基于异或运算或者Reed-Solomon(RS)编码,我们的CBFS也采用了RS编码。
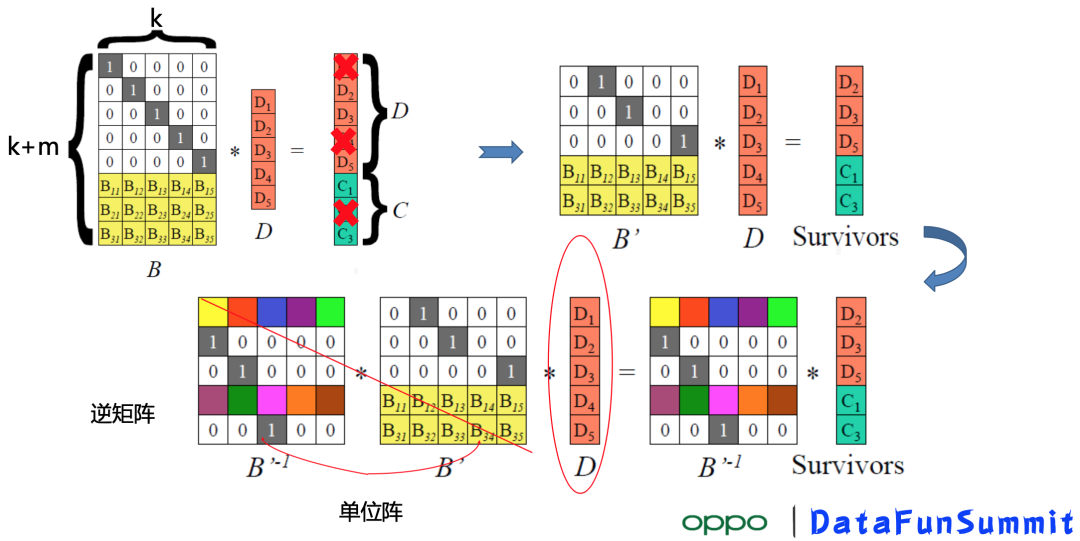
计算步骤:
编码矩阵B∈R(k+m)×k,上面n行是单位阵I,下方m行是编码矩阵;k+m个数据块组成的向量,包含原始的数据块和m个校验块;
当某块丢失时:从矩阵B删除该块对应的行,得到新的矩阵 B',然后左边乘上B'的逆矩阵,即可恢复丢失的块,详细计算过程大家可线下阅读相关资料。
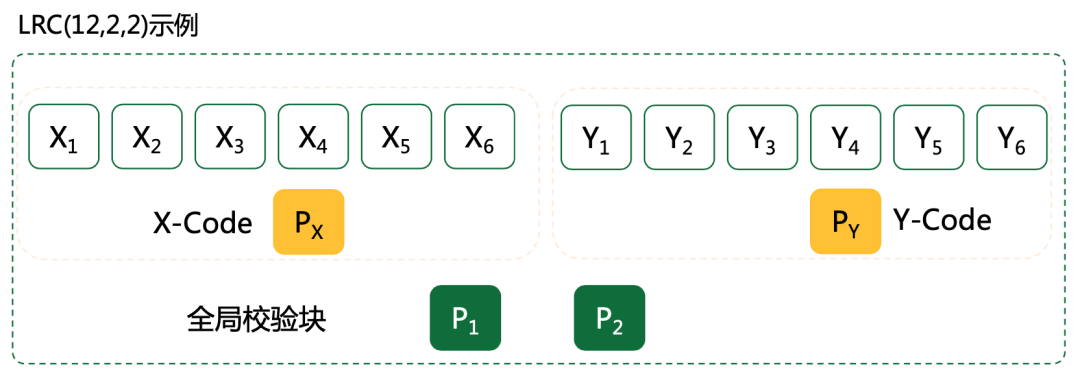
普通的RS编码存在一些问题:以上图为例,假设X1~X6 ,Y1~Y6为数据块,P1和P2为校验块,若其中任意一块丢失,需要读其余12个块才能修复数据,磁盘IO损耗大,数据修复所需带宽高,在多AZ部署时,问题尤为明显;
微软提出的LRC编码,通过引入局部校验块来解决该问题,如图所示,在原来全局校验块P1和P2的基础上,新增2个局部校验块PX和PY,假设X1损坏,只需读取与其关联X1~X6共6个块即可修复数据。统计表明,在数据中心,一个条带在一定时间内单块盘故障的概率是98%,2个盘同时损坏的概率是1%,因此LRC在大多数场景可大幅提升数据修复效率,但缺点是其非最大距离可分编码,无法做到像全局RS编码那样损失任意m份数据能把所有的丢修复回来。
① EC类型
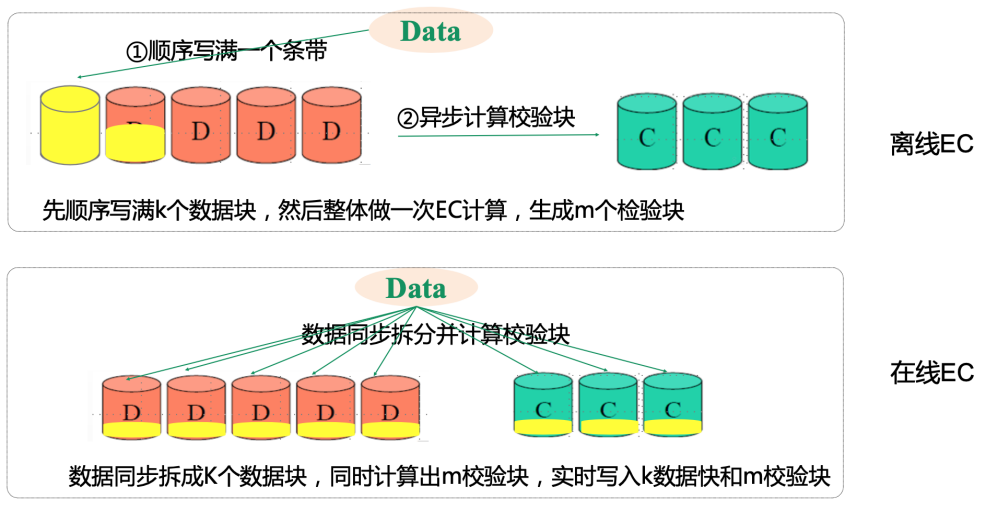
- 离线EC:整个条带k个数据单元都写满后,整体计算生成m校验块
- 在线EC:收到数据后同步拆分并实时计算校验块后,同时写入k个数据块和m个校验块
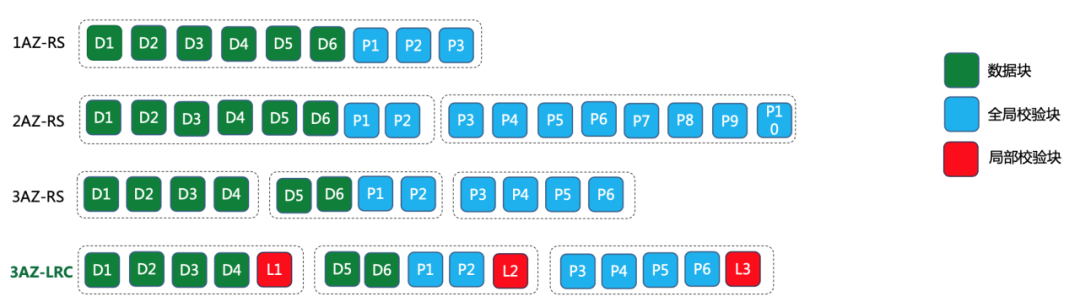
② CBFS跨AZ多模式在线EC CBFS支持了跨AZ多模式条带的在线EC存储,针对不同的机房条件(1/2/3AZ)、不同大小的对象、不同的服务可用性和数据耐久性需求,系统可灵活配置不同的编码模式
以图中“1AZ-RS”模式为例,6个数据块加3个校验块单AZ部署;2AZ-RS模式,采用了6个数据块加10个校验块2AZ部署,数据冗余度为16/6=2.67;3AZ-LRC模式,采用6个数据块,6个全局校验块加3个局部校验块模式;同一个集群内同时支持不同的编码模式。
③ 在线EC存储架构
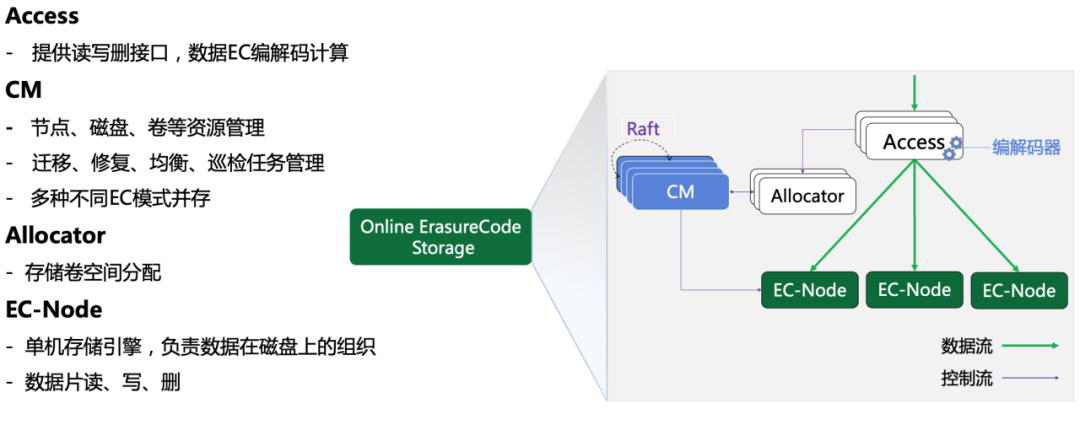
包含几个模块:
Access: 数据访问接入层,同时提供EC编解码能力
CM:集群管理层,管理节点,磁盘,卷等资源,同时负责迁移,修复,均衡,巡检任务,同一个集群支持不同EC编码模式并存
Allocator:负责卷空间分配
EC-Node:单机存储引擎,负责数据的实际存储
④ 纠删码写
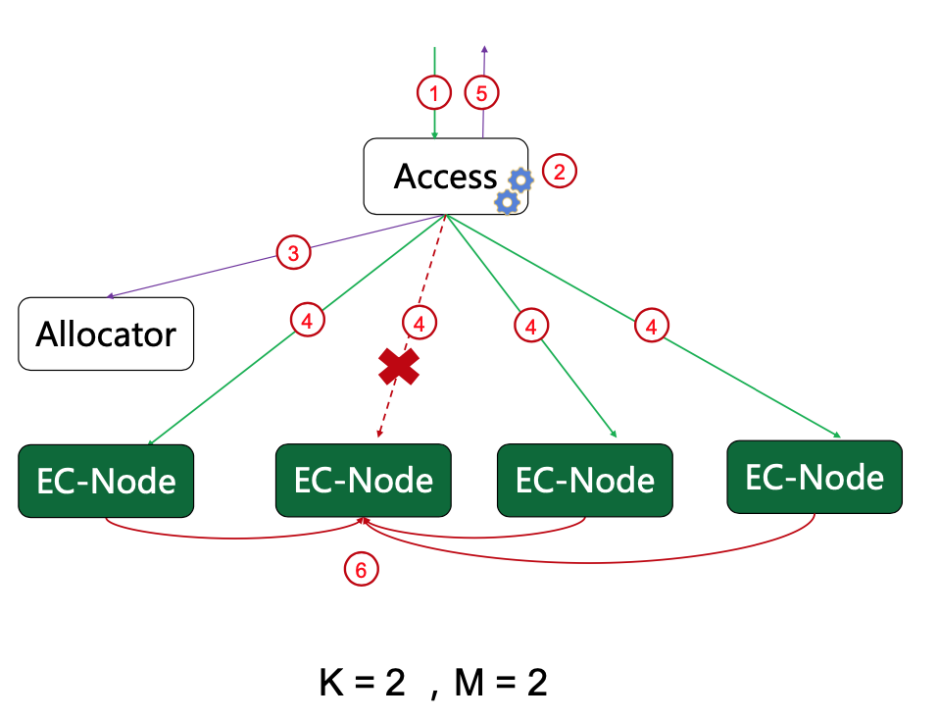
- 流式收取数据
- 对数据切片生成多个数据块,同时计算校验块
- 申请存储卷
- 并发向各个存储节点分发数据块或校验块
数据写入采用简单的NRW协议,保证最小写入份数即可,这样在常态化的节点及网络故障时,请求也不会阻塞,保障可用性;数据的接收、切分、校验块编码采取异步流水线方式,也保障高吞吐和低时延。
⑤ 纠删码读
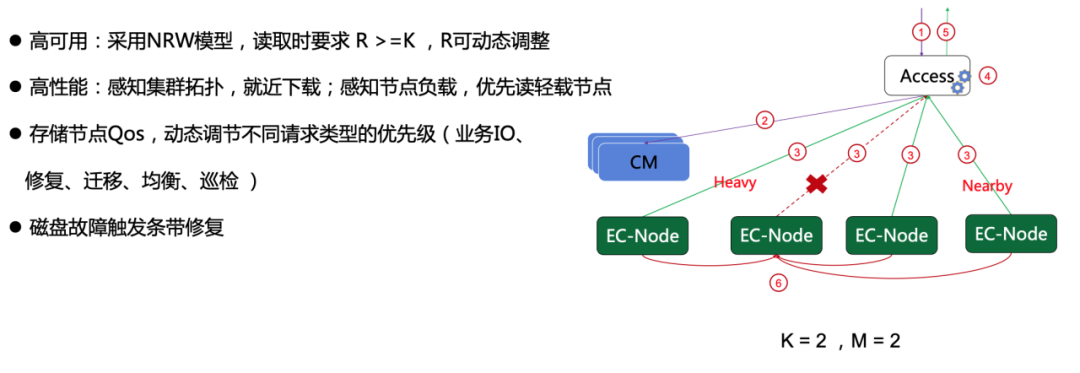
数据读取也采取了NRW模型,以k=m=2编码模式举例,只要正确读到2个块(不论是数据块还是校验块), 即可快速RS解码计算得到原始数据并;此外为提升可用性和降低时延,Access会优先读临近或低负载的存储节点EC-Node。
可以看到,在线EC结合NRW协议确保了数据的强一致性,同时保障高吞吐和低时延,很适合大数据业务模型。
数据湖访问加速
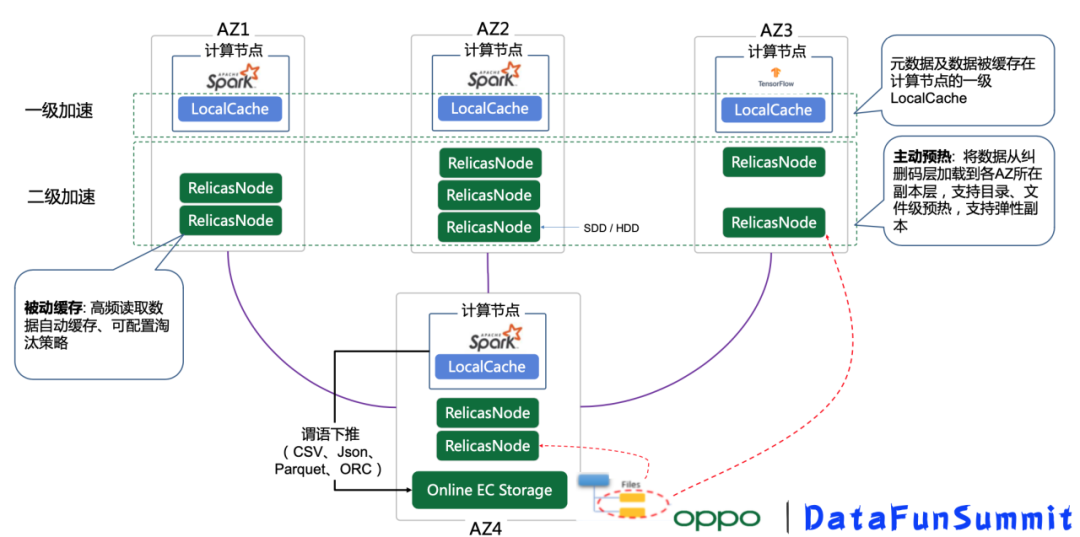
数据湖架构带来显著的收益之一是成本节约,但存算分离架构也会遇到带宽瓶颈和性能挑战,因此我们也提供了一系列访问加速技术:
① 多级缓存能力
- 第一级缓存:本地缓存,其与计算节点同机部署,支持元数据和数据缓存,支持内存、PMem、NVme、HDD不同类型介质,特点是访问时延低,但容量少
- 第二级缓存:分布式缓存,副本数目弹性可变,提供位置感知能力,支持用户/桶/对象级的主动预热和被动缓存,数据淘汰策略也可配置
多级缓存策略在我们的机器学习训练场景有不错的加速效果。
② 谓语下推操作
另外存储数据层还支持了谓语下推操作,可显著减少存储与计算节点间大量的数据流动,降低资源开销并提升计算性能;
数据湖加速有还很多细致的工作,我们也在持续完善的过程中。
未来展望
目前CBFS-2.x版本已开源,支持在线EC、湖加速、多协议接入等关键特性的3.0版本预计将于2021年10月开源;后续CBFS会增加存量HDFS集群直接挂载(免数据搬迁),冷热数据智能分层等特性,以便支持大数据及AI原架构下存量数据平滑入湖。