
Data Lake Unified Storage Technology Practice

Guide
Oppo is a smart terminal manufacturing company with hundreds of millions of end users. The data generated by mobile phones and IoT devices is endless. The intelligent services of the devices need us to do deeper mining of this data. How to store mass data at low cost and use it efficiently is a problem that big data department must solve. The popular solution in the industry is the data lake, this teacher Xiaochun He introduced the OPPO self-developed data lake storage system CBFS to a large extent can solve the current pain point. This article will start with the following points:
Data Lake Storage Technology is introduced briefly
The architecture design of Oppo Data Lake Storage CBFS
The key technology of Data Lake Storage CBFS
The future of Data Lake Storage CBFS
Data lake briefly
Data Lake Definition: A centralized repository that stores data in its original data format, usually Binary blob or files. A data lake is usually a single data set, including raw data as well as transformed data (reporting, visualization, advanced analysis, machine learning, etc.) .
The value of Data Lake storage
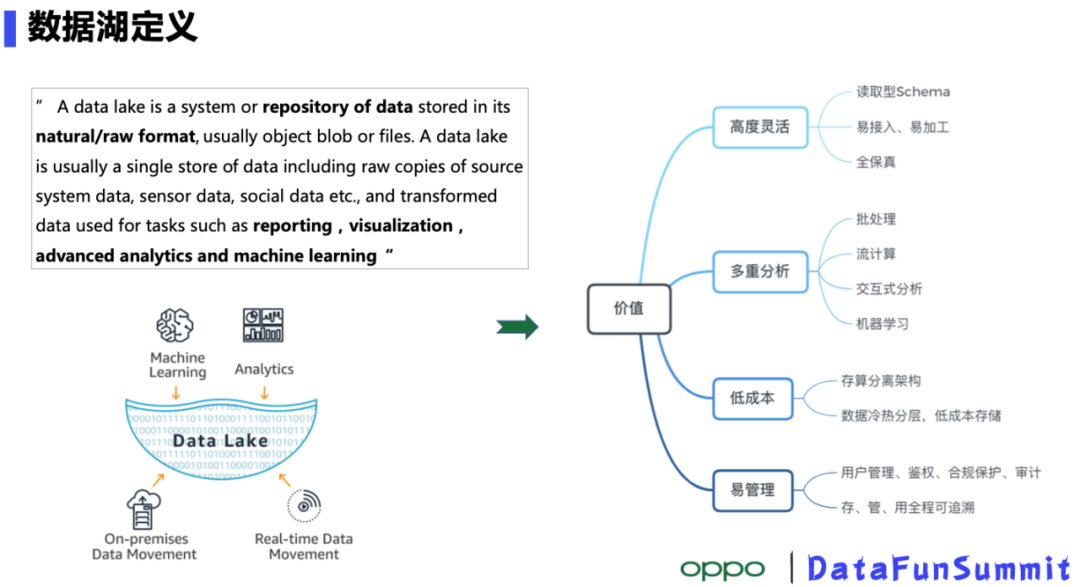 In contrast to the traditional Hadoop architecture, Data Lakes have several advantages:
In contrast to the traditional Hadoop architecture, Data Lakes have several advantages:
- Highly flexible: Data Reading, writing and processing are very convenient, can save all the original data
- Multi-analysis: support including batch, stream computing, interactive query, machine learning and other load
- Low Cost: storage computing resources independently expand; use object storage, hot and cold separation, lower cost
- Easy to manage: Perfect User Management Authentication, compliance and audit, data“Save” the whole process can be traced
Oppo data lake overall solution
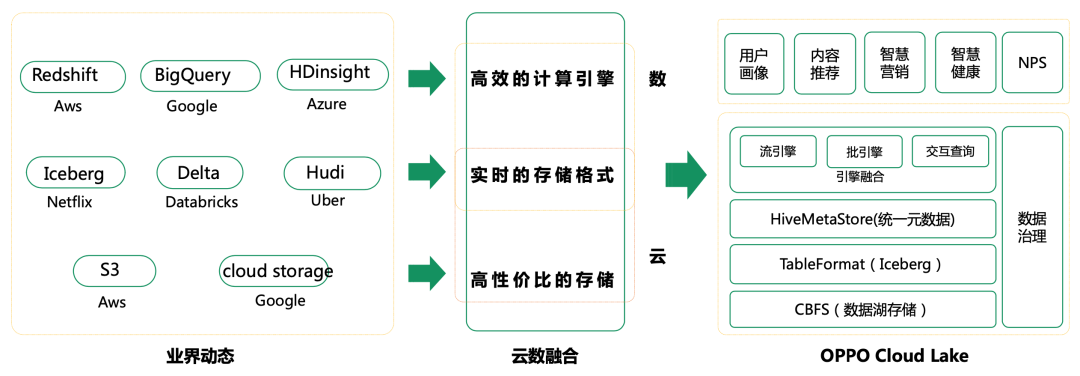
Oppo mainly constructs data lake from three dimensions: the lowest lake storage, which adopts CBFS, is a low-cost storage that supports s 3, HDFS, POSIX file access protocols; The middle layer is a real-time data storage format, using iceberg; the top layer can support a variety of different computing engines.
Oppo Data Lake architecture features
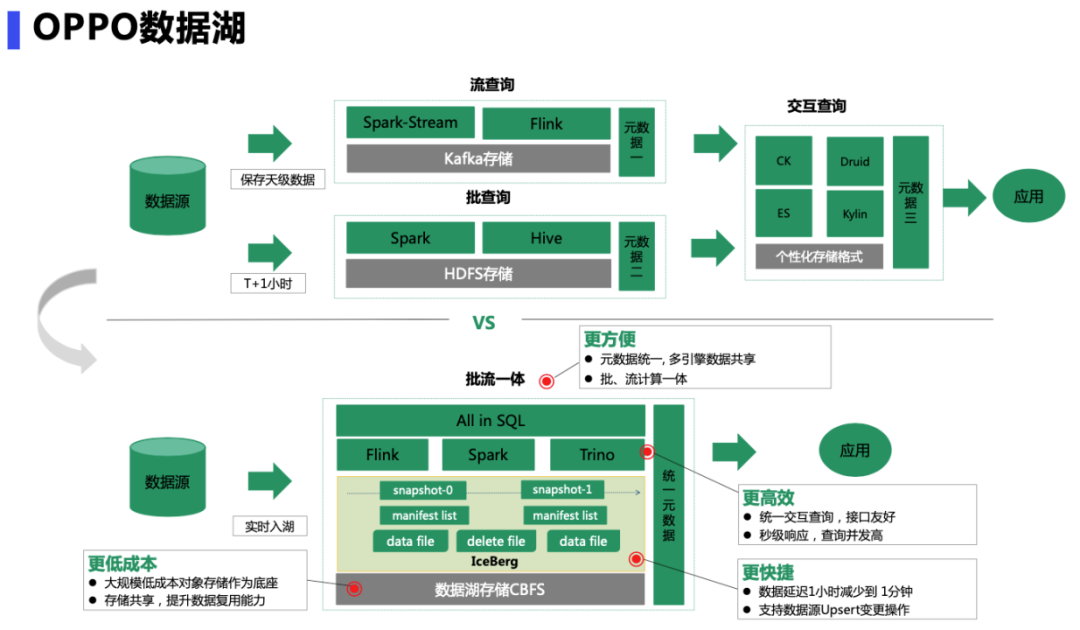 In the early days of big data storage, the storage of stream computing and batch computing was in different systems, the upgraded architecture unified metadata management, integrated batch and stream computing, and provided unified interactive query, the interface is more friendly, second-level response, high concurrency, and support data source Upsert change operations; the bottom layer adopts large-scale low-cost object storage as a unified data base, support multi-engine data sharing, improve data reuse capabilities
In the early days of big data storage, the storage of stream computing and batch computing was in different systems, the upgraded architecture unified metadata management, integrated batch and stream computing, and provided unified interactive query, the interface is more friendly, second-level response, high concurrency, and support data source Upsert change operations; the bottom layer adopts large-scale low-cost object storage as a unified data base, support multi-engine data sharing, improve data reuse capabilities
The data lake stores the CBFS schema
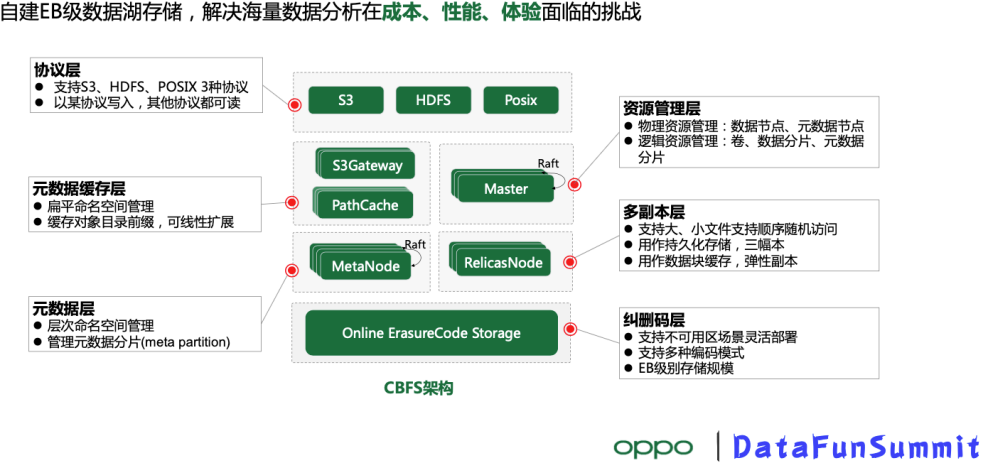
Our goal is to build a data lake that supports EB-level data and addresses the cost, performance, and experience challenges of data analytics. The entire data lake store is divided into six subsystems:
Protocol access layer: support a variety of different protocols (s 3, HDFS, POSIX files) , you can do data written with one of the protocols, with the other two protocols can also be read directly
Metadata Layer: the hierarchical namespace of the external rendering file system and the flat namespace of the object, the entire metadata is distributed, supporting fragmentation, linear extensibility
Metadata cache layer: Used to manage metadata cache and provide metadata access acceleration capabilities
Resource management layer: the Master node in the diagram is responsible for the management of physical resources (data nodes, metadata nodes) and logical resources (volume/bucket, Data Shard, Metadata Shard)
Multi-copy layer: support for append write and random write, large objects and small objects are more friendly. One function of the subsystem is to store multiple copies as persistence; the other is the data cache layer, which supports elastic copies, accelerates access to the data lake, and then unfolds
Erasing code storage layer: can significantly reduce storage costs, while supporting multi-available area deployment, support different erasing code model, easily support EB-level storage scale
Next, we'll highlight some of the key technologies used by CBFS, including high-performance metadata management, erasure code storage, and lake acceleration.
Key Technologies of CBFS
1. metadata management
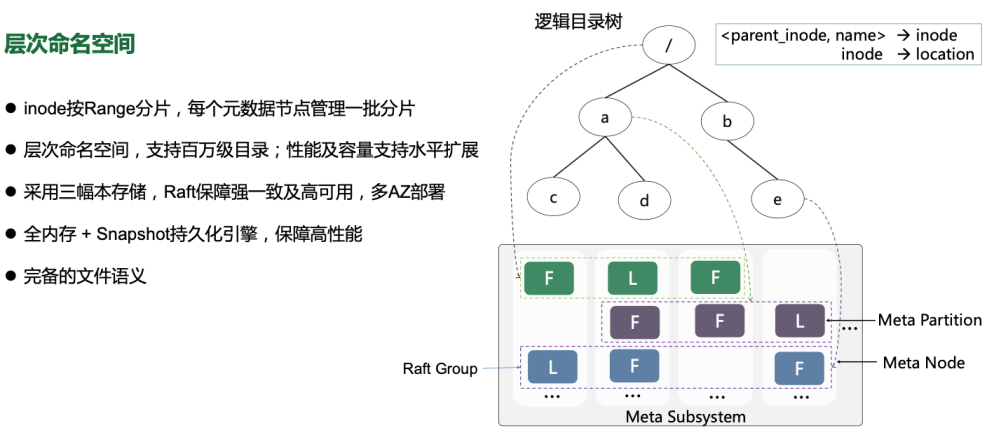
The file system provides a hierarchical namespace view, and the logical directory tree of the entire file system is divided into multiple layers, as shown in the right image. Each metadata node contains hundreds or thonds of metadata shards (MetaPartition) , each shard consists of InodeTree (BTree) and Dentrytree (BTree) , each dentry represents a directory entry, and DENTRY consists of parentId and name. In a DentryTree, it is stored and retrieved by indexing with partid and name; in an InodeTree, it is indexed with an inode ID. The multiRaft protocol guarantees high availability and consistent replication of data, and each node set contains a large number of shard groups, each of which corresponds to a raft group; each shard group belongs to a certain volume Each shard group is a range of metadata (an inode ID) for a volume; the metadata subsystem expands dynamically by splitting; and when a shard group resource (performance, capacity) is close to an adjacent value, the, the File Explorer service anticipates an end point, notifies the set of node devices that only serve data up to that point, and selects a new set of nodes that are dynamically added to the current business system.
A single directory supports million-level capacity, metadata is all in memory, ensuring excellent read and write performance, and memory metadata shards are persisted to disk by snapshot for backup and recovery purposes.
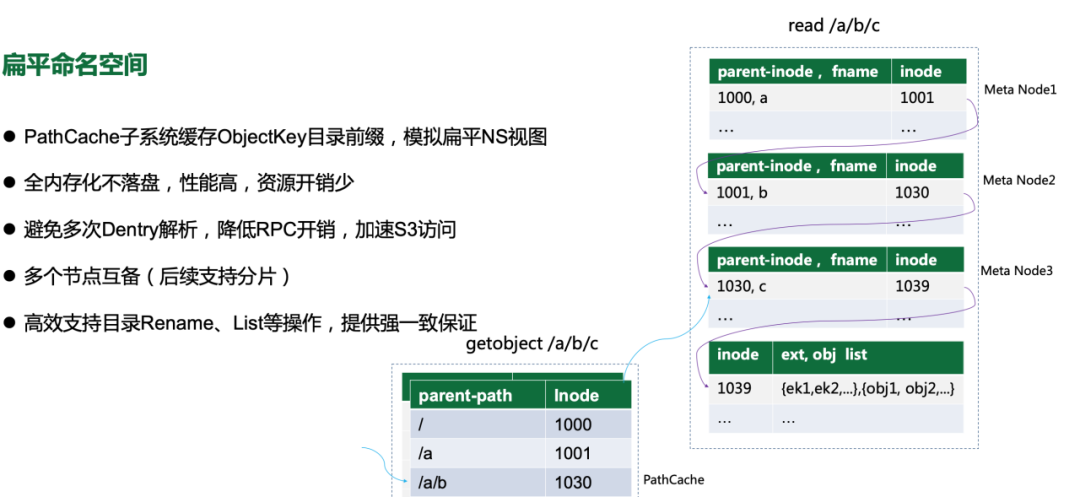
Object storage, on the other hand, provides a flat namespace; for example, to access an object whose objectkey is/bucket/A/b/c, starting from the root directory, through”/” delimiter layer-by-layer parsing, we found the Dentry of the last directory (/bucket/A/b/c) , and the Inode of the last directory (/bucket/A/b/c) . This process involves multiple interactions between nodes, and the deeper the layer, the worse the performance. Therefore, we introduced the PathCache module to speed up the ObjectKey parsing. A simple approach is to cache the Dentry of the parent directory (/bucket/A/B) of the ObjectKey in the PathCache. Analyzing the online cluster, we found that the average size of the directories is about 100, assuming the size of the storage cluster at 100 billion level, the directory entry is only 1 billion, the single-machine cache is very efficient, and the read performance can be improved through node expansion. In the design of supporting both“Flat” and“Hierarchical” namespace management, compared with other systems in the industry, CBFS is simpler and more efficient, and can easily implement one piece of data without any transformation. Multiple protocols can access each other, and there is no data consistency problem.
2. Erasure code storage
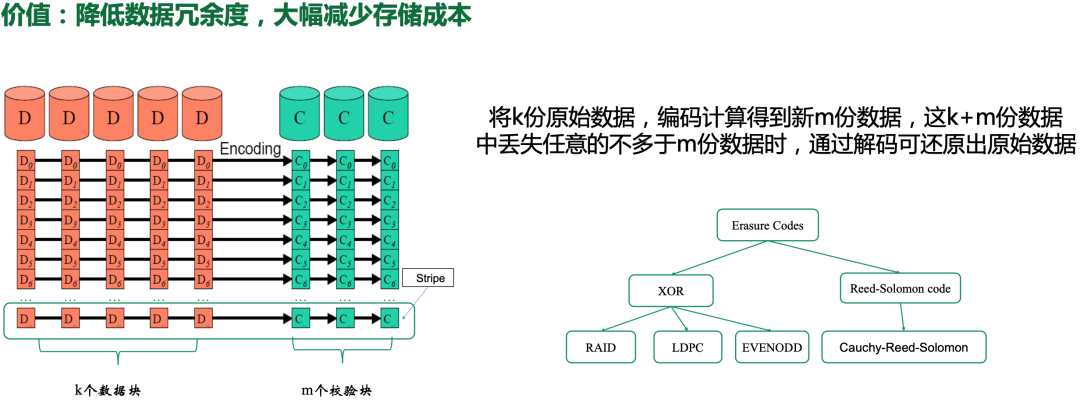
Erasure Code (EC) is one of the key technologies to reduce the cost of storage. This paper briefly introduces the principle of EC, the original data can be recovered by decoding when the number of K + M data lost is no more than M data, and the data redundancy of EC is lower than that of traditional multi-copy storage, but data durability is higher; there are many different ways to do this, most of which are based on XOR or or Reed-Solomon (RS) encoding, and our CBFS also uses RS encoding.
Steps:
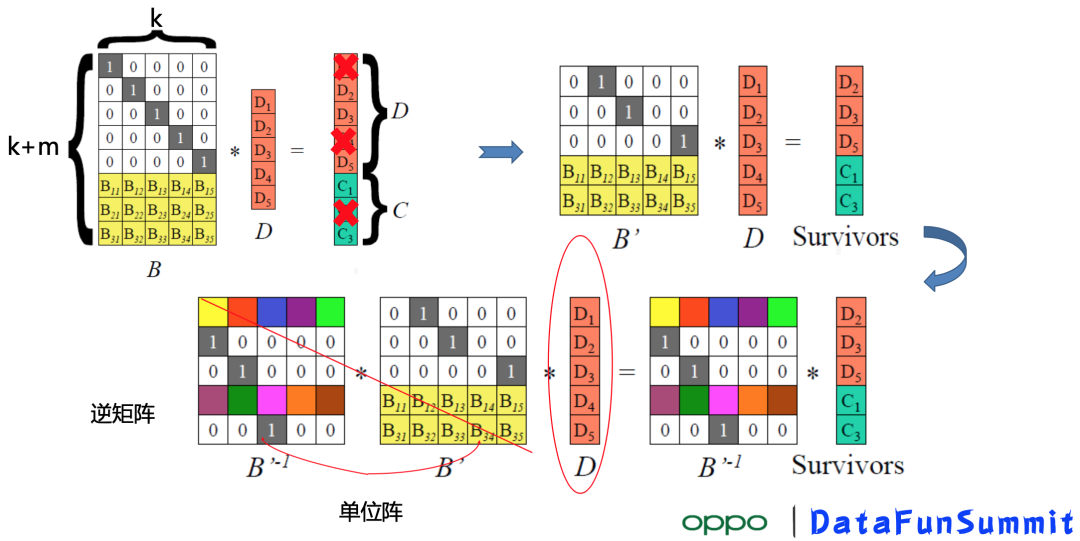
The coding matrix B ∈ R (K + M) × K, the upper row N is the identity matrix I, the lower row M is the coding matrix, the vector composed of K + m data blocks contains the original data blocks and M check blocks;
When a block is lost: deletes the corresponding row of the block from matrix B, get the new matrix B' , and then the left times the inverse of the matrix B' , you can recover the lost blocks, detailed calculation process you can read the relevant information offline.
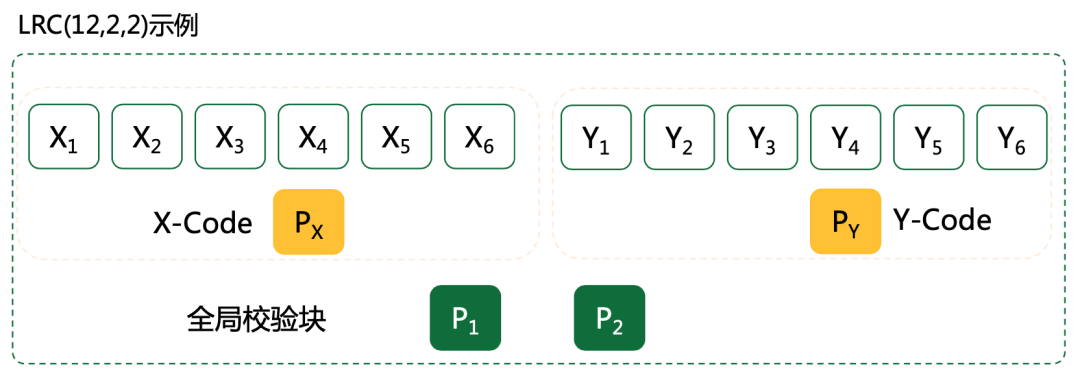
There are some problems in ordinary RS coding: for example, suppose X 1-x 6, Y 1-y 6 are data blocks, P 1 and P 2 are check blocks, if any one of them is lost, need to read the remaining 12 blocks to repair the data, disk IO loss, data repair requires high bandwidth, multi-AZ deployment, the problem is particularly obvious;
The LRC code proposed by Microsoft solves this problem by introducing local check blocks. As shown in the figure, two new local check blocks PX and PY are added on top of the original global check blocks P 1 and P 2, assuming X 1 is corrupted, only six blocks of X 1-x 6 associated with it need to be read to fix the data. Statistics show that in data center, the probability of failure of a single disk is 98% , and the probability of two disks being damaged at the same time is 1% . Therefore, LRC can greatly improve the efficiency of data repair in most scenarios, however, its disadvantage is that it can not be decomposed by non-maximum distance, and can not recover all the lost M data as the global RS Coding.
① EC Type
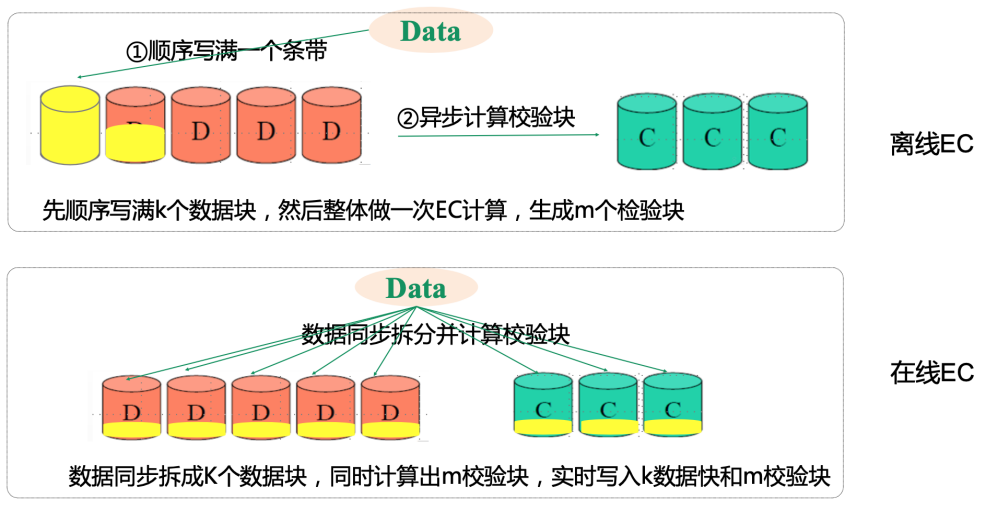
Off-line EC: the whole strip K data units are written, the overall calculation generated M check block
On-line EC: after receiving the data, synchronously split and real-time calculate the check block, write K data block and M check block at the same time
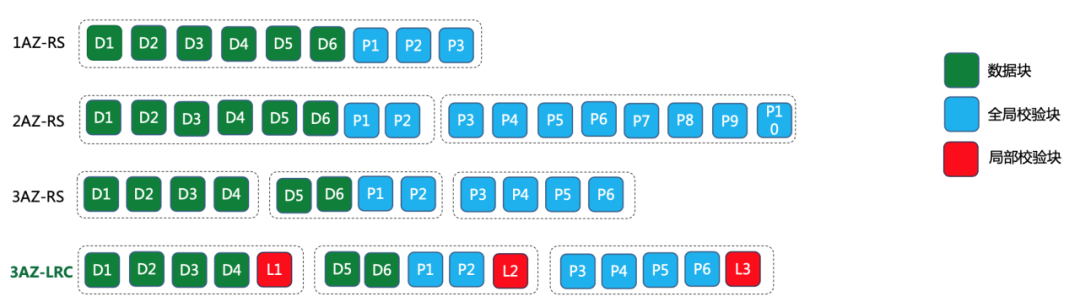
② CBFS Multimodal Online EC Across AZ CBFS supports on-line EC storage across AZ multi-mode bands for different room conditions (1/2/3AZ) , different size objects, different service availability and data durability requirements, the system has the flexibility to configure different encoding modes
Taking the“1AZ-RS” model as an example, 6 data blocks plus 3 checksum blocks are deployed in single AZ mode, while in 2AZ-RS model, 6 data blocks plus 10 checksum blocks are deployed in 2AZ mode, the data redundancy is 16/6 = 2.67; 3AZ-LRC mode, 6 data blocks, 6 global blocks plus 3 local blocks mode; support different coding modes in the same cluster.
③ Online EC storage architecture
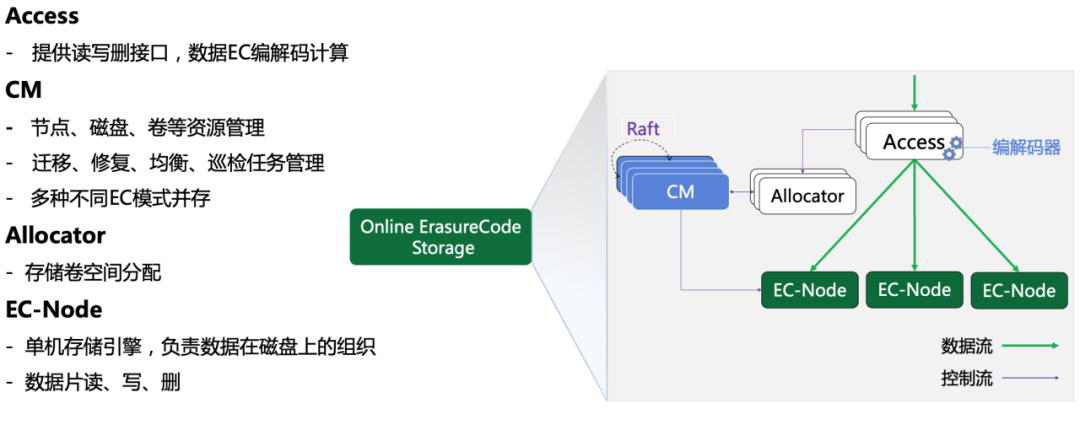
Contains several modules:
Access: data Access Access layer, while providing EC encoding and decoding capabilities
CM: cluster management layer, management node, disk, volume and other resources, also responsible for migration, repair, equalization, patrol tasks, the same cluster to support the coexistence of different EC coding mode
Allocator: responsible for volume space allocation
EC-Node: Stand-alone storage engine, responsible for the actual storage of data
④ Write the correction code
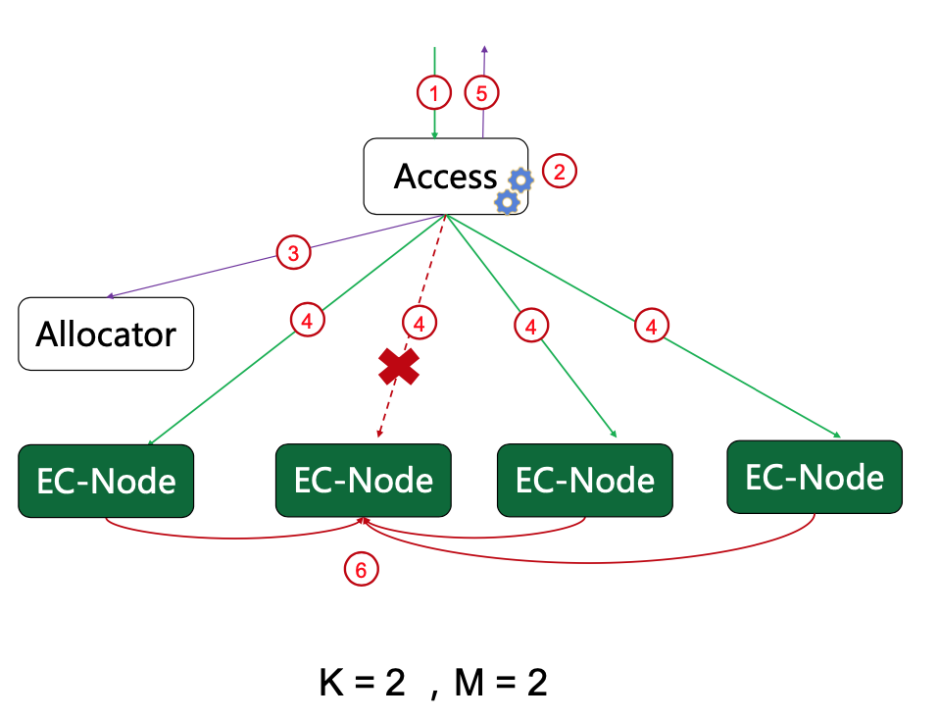
- Stream receive data
- Generate multiple data blocks on the data slice, and compute the check block at the same time
- Apply for a storage volume
- A data block or a check block is distributed concurrently to each storage node
Simple NRW protocol is used to write the data, and the minimum number of copies is guaranteed. In this way, the request will not be blocked when the normal node and the network fail, and the availability is guaranteed The data receiving, segmentation and check block coding are asynchronous pipelined to ensure high throughput and low delay.
⑤ Read the correction code
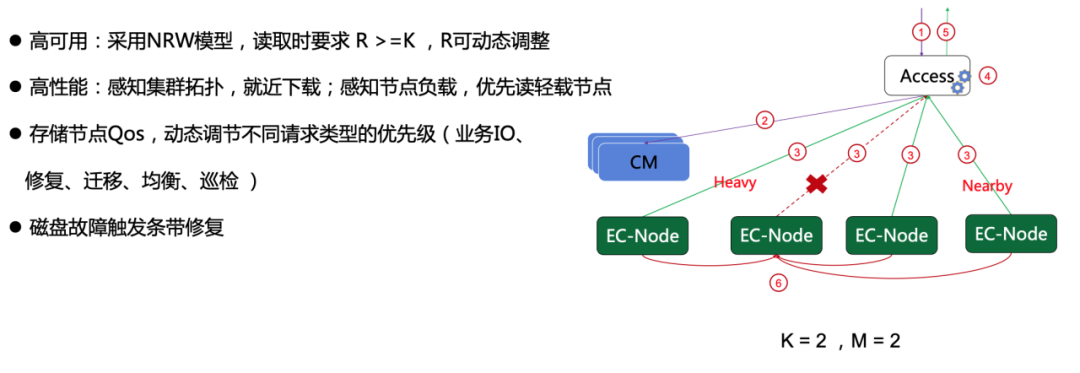
The NRW model is also adopted for data reading. Taking the K = m = 2 encoding mode as an example, as long as two blocks are read correctly (either data block or check block) , the original data can be obtained by Fast RS decoding In addition, to improve availability and reduce latency, Access preferentially reads the nearby or low-load storage node EC-Node.
It can be seen that online EC combined with NRW protocol ensures strong data consistency, high throughput and low latency, which is suitable for big data business model.
3. Data Lake access speeds up
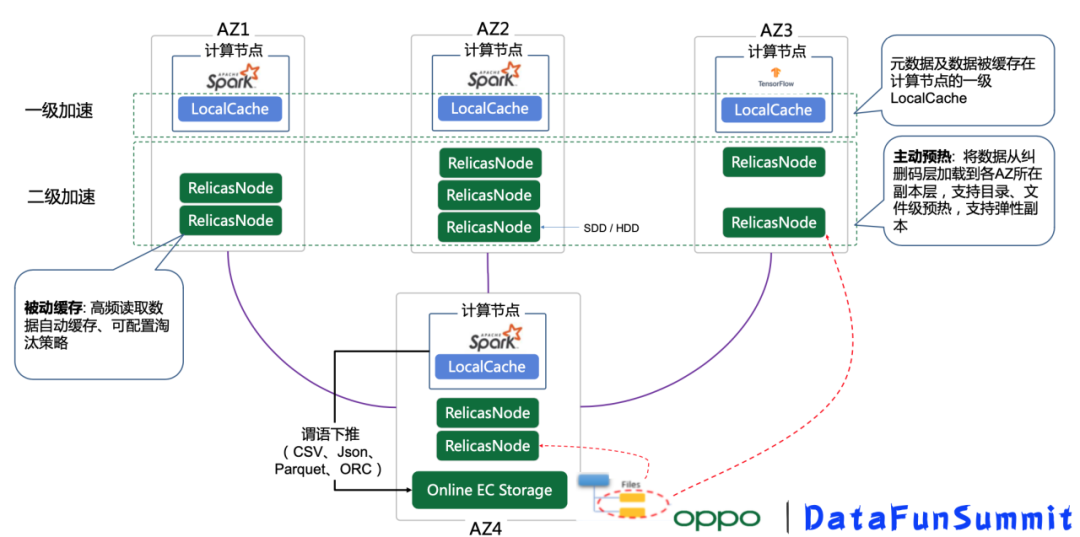
One of the significant benefits of the data lake architecture is cost savings, but the separate storage and computing architecture also faces bandwidth bottlenecks and performance challenges, so we also offer a number of access acceleration techniques:
① Multi-level cache capability
- First-level cache: Local Cache, which is co-deployed with computing nodes, supporting metadata and data cache, supporting memory, PMEM, NVme, HDD different types of media, characterized by low access delay, but less capacit
- Second-level cache: Distributed Cache, flexible copy count, location-aware, user/bucket/object-level active and passive cache support, and data obsolescence policy can be configured
The multi-level caching strategy had a good acceleration effect in our ML training scenario.
② Predicate push-down operation
In addition, the storage data layer also supports predicate push-down operation, which can significantly reduce the amount of data flow between storage and computing nodes, reduce resource overhead and improve computing performance
There is still a lot of detailed work to speed up the data lake, and we are in the process of continuous improvement.
future expectations
Currently CBFS-2. Version X is open source, and version 3.0, which supports key features such as online EC, Lake Acceleration, and multi-protocol access, is expected to be open source in October of the 2021; Future CBFS will increase the storage HDFS cluster directly mount (no data migration) , hot and cold data intelligent hierarchical features, in order to support big data and AI under the original structure of storage data smooth into the lake.