
CubeFS Best Security Practices
Authentication
AK and SK
AK (Access Key) and SK (Secret Key) are secure credentials used for authentication and access control, commonly used in cloud service providers and other online platforms. AK is the user's access key, similar to a username, used to identify the user's identity. SK is the associated key with AK, similar to a password, used to verify the user's identity and generate digital signatures to ensure data security. Proper management and usage of AK and SK are crucial in the security domain. Here are some best practices for AK and SK security:
- Confidentiality: AK and SK should be securely stored and only provided to trusted entities (such as applications or services) when necessary. They should not be stored in publicly accessible locations, such as version control systems, public code repositories, or public documents.
- Regular Rotation: Regularly rotating AK and SK is a good security practice to mitigate the risk of key misuse. It is recommended to change keys periodically, such as every few months or as per security policies and standards requirements.
- Permission Control: Setting appropriate permissions and access controls for each AK and SK is vital. Only grant the minimum required privileges to perform specific tasks, and regularly review and update permission settings to ensure the principle of least privilege is always maintained.
- Encrypted Transmission: When using AK and SK for authentication, secure transmission protocols (such as HTTPS) should be employed to protect the credentials during the transmission process, preventing interception or tampering by man-in-the-middle attacks.
- Strong Password Policy: Selecting strong passwords and following password policies is an important measure to protect SK. Passwords should have sufficient complexity, including a combination of uppercase and lowercase letters, numbers, and special characters, while avoiding easily guessable or common passwords.
In conclusion, ensuring the security of AK and SK is crucial for safeguarding the security of systems and data. By strictly adhering to security best practices and properly managing and using AK and SK, security risks can be mitigated, and the effectiveness of authentication and access control can be ensured.
AuthNode:Authentication Module
Requirements: Add authentication to the Master node or other important interfaces in the access process to prevent unauthenticated clients and internal nodes from joining the cluster. Verification is required when important information is pulled.
Principles: Authnode is a secure node that provides a universal authentication and authorization framework for CubeFS. In addition, Authnode serves as a centralized key storage for both symmetric and asymmetric keys. Authnode adopts and customizes the ticket-based Kerberos authentication concept. Specifically, when a client node (Master, MetaNode, DataNode, or client node) accesses the service, it needs to present a shared key for authentication to Authnode. If the authentication is successful, Authnode issues a time-limited ticket specifically for that service. For authorization purposes, functionality is embedded in the ticket to indicate who can do what on which resources.
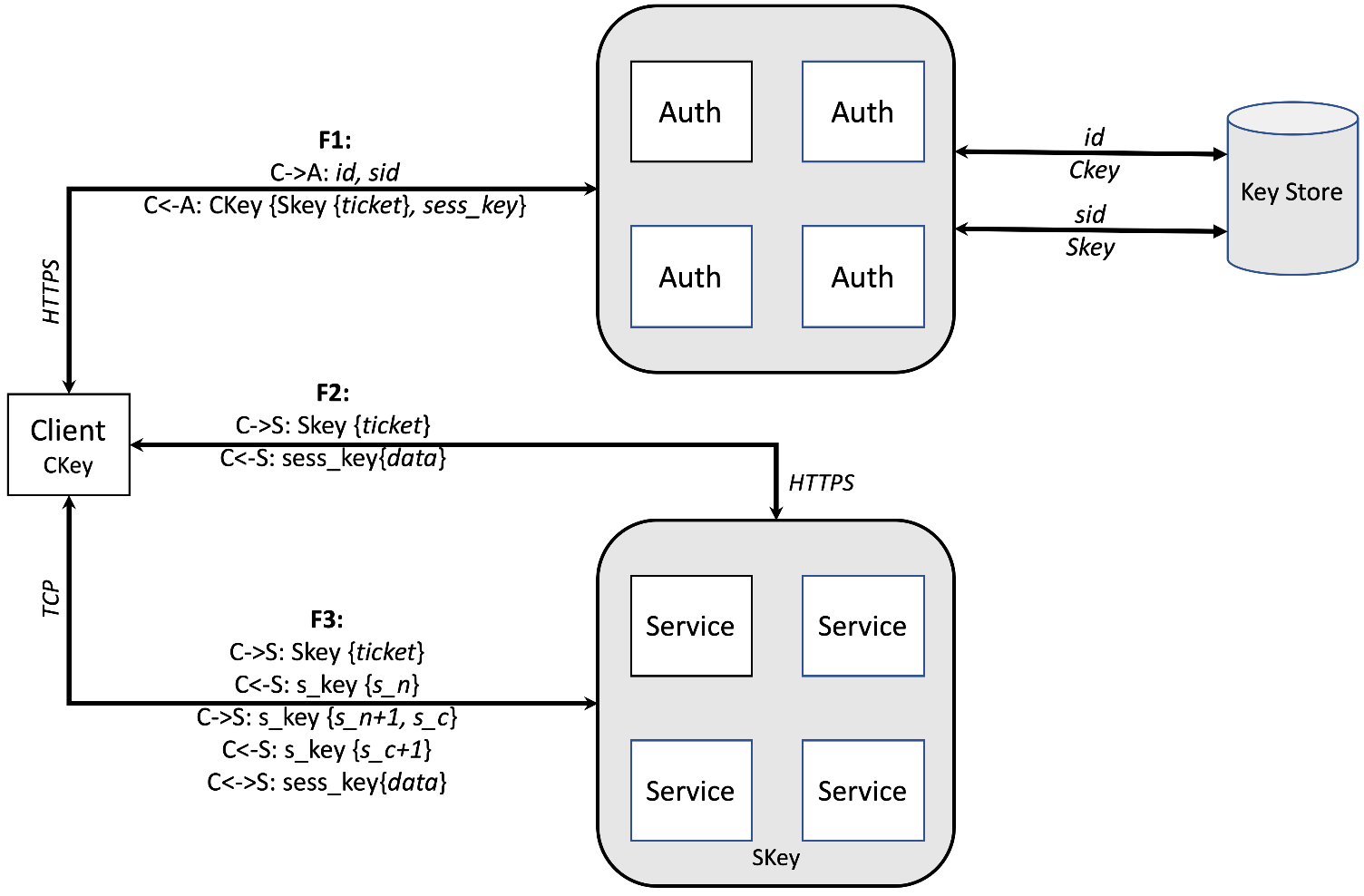
- Startup Configuration steps in CubeFS (refer to docker/run_docker4auth.sh)
- The super administrator uses the key of authnode and can generate exclusive keys for each module through the
createKey API. For example, the client isCkeyand the master isSkey.At the same time, the corresponding relationship between module ID and Key will be stored in AuthNode; - Configure ID and Key for each module and start the service.
- The super administrator uses the key of authnode and can generate exclusive keys for each module through the
- Expand the scope of Master interface verification The Master interface requires a significant amount of operational management at both the volume and cluster levels. It is essential to ensure the security of cluster management. To achieve this, you can enable the
authenticateconfiguration on the Master. This will require interface operations to undergo a secondary verification of the correctness at Authnode.
Authorization Policies and Management
Permission Levels
- Permissions are divided into admin privileges and regular user privileges. Admin privileges include management privileges of regular users and operational privileges at the volume level, which are displayed in the system through the
ownerfield. - Regular user privileges are based on admin authorization and have fixed access paths (such as the root directory) and operational permissions (read, write). Users can only operate on files or directories within their own mounted directory and its subdirectories.
- From the perspective of volumes, users are classified into two types: read-only users and read-write users. Read-only users can only read files or directories and cannot modify them. Additionally, it is possible to restrict users to access only specific subdirectories. After mounting, CubeFS supports permission checks based on Linux user, group, and other permission restrictions. For example, given the following file permissions:
-rwxr-xr-x 2 service service f1, only theserviceuser can modify the file, while other non-root users can only read it.
User managment:https://cubefs.io/docs/master/tools/cfs-cli/user.html
Permission Management
The creation request goes through the governance platform for approval. After creation, the usage of the owner (admin) can be tightened, with the ability to delete volumes. The admin account for the volume is created and managed by the governance platform, automatically generated based on naming rules. Sharing a single admin account is otherwise insecure, so a regular account is provided to the business.
For example: When integrating with middleware, a regular account is authorized and provided to the business. The governance platform retains the owner information, and any deletion requests need to be submitted through the governance platform for approval.
ladp+autoMount
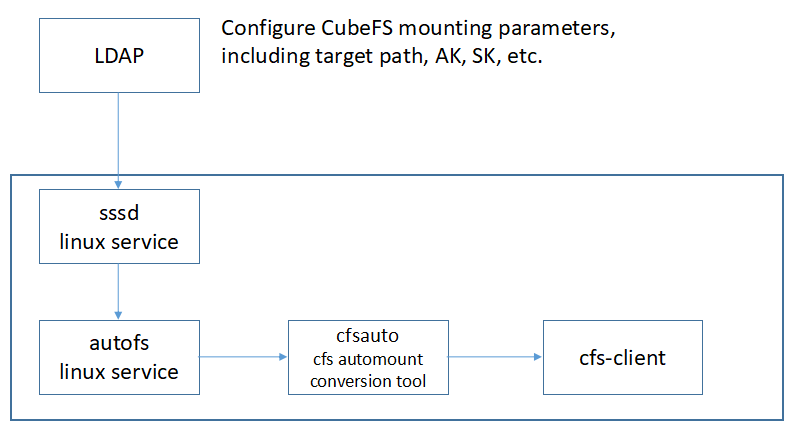
The role of LDAP
- User Authentication: LDAP can be used to authenticate user identities. Usernames and passwords can be stored in an LDAP directory, and when a user attempts to authenticate, the system can communicate with the LDAP server via the LDAP protocol to verify if the credentials provided by the user match those stored in the directory.
- Single Sign-On (SSO): LDAP can serve as an authentication backend for a Single Sign-On system. SSO allows users to log in to multiple associated applications using a single set of credentials, eliminating the need for separate authentication for each application. By using LDAP as the authentication backend, user credentials can be managed centrally, enabling a seamless login experience across multiple applications.
- User Authorization and Permission Management: The LDAP directory can store user organizational structure, roles, and permission information. An LDAP-based authentication and authorization system can grant users appropriate permissions and access based on their identity and organizational structure. This ensures that only authorized users can access sensitive data and resources, enhancing system security.
- Centralized User Management: LDAP provides a centralized user management platform. Organizations can store and manage user information, including usernames, passwords, email addresses, phone numbers, etc., in an LDAP directory. Through LDAP, administrators can easily add, modify, or delete user information without the need for individual operations in each application, improving management efficiency and consistency.
Advantages of automatic mounting
- AK and SK should be properly safeguarded and only provided to trusted entities (such as applications or services) when necessary. AK and SK should not be stored in publicly accessible locations, such as version control systems, public code repositories, or public documents.
- To prevent the leakage of AK, SK, and other sensitive information, it is important to enhance the security and availability of keys.
- LDAP-based authentication can be implemented using IP and user-based verification. LDAP can also be utilized for controlling and managing permissions.
GateWay
The master IP is not directly exposed, and a domain name approach is used through a gateway. The advantages are as follows:
- Easy master node replacement: Using a domain name approach avoids the need for client configuration changes. Under normal circumstances, it can be cumbersome to update business configurations and restart them.
- Ensuring interface security: The necessary master interfaces, such as partition information required by programs, can be exposed through the domain name. However, management interfaces are not exposed externally, protecting administrative privileges.
- Serving for monitoring, alerting, and success rate statistics: The domain name approach enables monitoring, alerting, and success rate statistics to be performed effectively.
- Adding a caching layer: Implementing a caching layer becomes feasible with the domain name approach.
Flow Control
Volume-level Read/Write Access Traffic QoS
In the multi-tenant operation mode of large-scale clusters, resource utilization can be improved and costs can be reduced, but it also brings challenges to system stability. For example, when a large number of requests for a volume under a tenant suddenly increase, the traffic impacts the entire storage system:
Different volumes' data and metadata partitions may be placed on the same machine or even the same disk. A large read/write request for a certain volume will affect the access of other volumes on the same node and disk.
When the bandwidth is full, it will affect internal communication between cluster nodes, further affecting the judgment of the cluster management node on the status of data nodes, triggering behaviors such as data balancing, and further exacerbating the shaking of the entire cluster.
Impacting the upstream switch of the cluster will not only affect the storage system itself but also affect other non-storage systems under the same switch.
Therefore, traffic QoS is an important means of ensuring stable operation of the system.
- Design document:
https://mp.weixin.qq.com/s/ytBvK3MazOzm3uDtzRBwaw - User document:
https://cubefs.io/zh/docs/master/maintenance/admin-api/master/volume.html#%E6%B5%81%E6%8E%A7
Master Request Interface QoS Limitation
- The stability of the Master node is crucial for the entire cluster. To prevent accidents (such as excessive retries in case of failures) or malicious attacks, it is necessary to implement QPS (Queries Per Second) rate limiting management for the Master's interfaces
- QPS rate limiting sets a limit on the number of requests the Master can accept per second. For interfaces without rate limiting set, no restrictions are applied. For interfaces with rate limiting configured, there is an option to set a timeout for rate limiting waits, preventing the occurrence of cascading failures.
Object Service Security-Related Features
S3 Authentication Capability
To ensure the security of data and request processes in CubeFS, all requests are either signed and authenticated or anonymously authorized. CubeFS's signature mechanism protects the security of user data in the following dimensions:
Requester Identity Authentication: Requesters must authenticate their identity through signature calculations using Access Key (AK) and Secret Key (SK). The server can identify the requester's identity through the AK.
Data Integrity: To prevent data tampering during transmission, the request elements are included in the signature calculation. Upon receiving a request, the server performs a signature calculation using the received request elements. If the request elements have been tampered with, the signature comparison between the client and server will not match.
ObjectNode supports three compatible S3 protocol signature algorithms: V2, V4, and STS. It also supports three sub-signature methods: Header, Query, and Form, ensuring the data security of user requests throughout the process.
Permission Control
- Permission control is an authorization strategy based on users and resources, which regulates access to user actions. Common application scenarios include controlling user and API combinations, controlling client IP addresses, request referers, and implementing internal and external network isolation access control.
- CubeFS provides the following permission control strategies primarily for accessing storage buckets and objects: Bucket Policy and ACL. In CubeFS's permission control, the first validation performed is the Bucket Policy. Only when a bucket does not have a set policy or the policy does not match the corresponding permissions, will ACL validation be performed.
WORM Mode
Object Lock enables the storage of objects in a Write Once, Read Many (WORM) mode. Object Lock allows users to comply with regulatory requirements for WORM storage and provides additional protection to prevent objects from being modified or deleted.
- An interface is provided to users for setting (canceling) and retrieving the Bucket object lock configuration. Once the Bucket object lock is configured by the user, all newly uploaded objects will adhere to this configuration, while existing objects remain unaffected.
- Users are provided with the functionality to retrieve the retention period and retention mode of objects through the HeadObject and GetObject methods. During the object lock protection period, objects cannot be deleted or overwritten.
S3API QoS
To ensure the availability of CubeFS services and mitigate the impact of abnormal user traffic, ObjectNode supports flow control policies at the concurrency, QPS (Queries Per Second), and bandwidth dimensions for different users under the S3API level.
ACL IP BlackList
Strengthening client-side control, we provide IP-based blocking policies for business and operations managers. Once an IP address belonging to a client mounting requests or an already mounted client is added to the blacklist, it will no longer be able to access the service. For example:
Preventing unauthorized access: ACL IP blacklisting can be used to block access from known malicious IP addresses, thus protecting network resources from unauthorized access or attacks.
Blocking malicious traffic: It helps to block malicious traffic from these sources, such as distributed denial of service (DDoS) attacks, malicious scanning, or web crawling.
Usage Methods:
./cfs-cli acl
Manage cluster volumes acl black list
Usage:
cfs-cli acl [command]
Aliases:
acl, acl
Available Commands:
add add volume ip
check check volume ip
del del volume ip
list list volume ip list
Firewall Port Range
The master, datanode, metanode, authnode, objectnode, lcnode, and other server-side components have a range of listening ports. It is recommended to only open necessary ports and close unnecessary ones. This can be achieved through firewall rules or system configurations. For example, if you only need to remotely manage the system via SSH, you can close other unnecessary remote management ports such as Telnet.
Audit Log
The operation audit trail of the mount point is stored in a locally specified directory on the client, making it convenient to integrate with third-party log collection platforms.
- The local audit log feature can be enabled or disabled in the client configuration.
- Clients can also receive commands via HTTP to actively enable or disable the log feature without the need for remounting.
- The client audit logs are recorded locally, and when a log file exceeds 200MB, it is rolled over. The outdated logs after rolling over are deleted after 7 days. In other words, the audit logs are retained for 7 days by default, and outdated log files are scanned and deleted every hour.
Starting from version 3.3.1, client-side auditing is enabled by default. However, instead of storing audit logs on the client, they are now stored on the server. Server-side auditing can be configured to enable or disable it, with the default setting being disabled.
Delete Protection.
At the volume level, a prohibition period can be set for a file or directory after its creation, during which it is not allowed to be deleted.
Users can use the CLI tool to set the deletion lock period and check if the parameter value passed is greater than 0. If it is greater than 0, the deletion lock period of the volume is updated with that value.
- The client periodically fetches volume information from the master and caches it. The deletion lock feature is only enabled on the client after the volume information is successfully fetched.
- Before executing a deletion, the client checks if the deletion lock period in the cached volume information is non-zero, indicating that the deletion lock feature is enabled. In this case, further checks are performed. If the deletion lock period set on the current volume is less than the difference between the current time and the creation time of the file or directory, the deletion can proceed with the subsequent logic.
- By default, the deletion lock feature is disabled for volumes. To enable this feature, it can be turned on during the volume creation or update process.
volume create:volume create [VOLUME NAME] --deleteLockTime=[VALUE]
volume update:volume update [VOLUME NAME] --deleteLockTime=[VALUE]