
CubeFS v3.0.0 Official Release
Summary
Version 3.0.0 introduces the following key features to adapt to more business scenarios:
- Hybrid cloud acceleration based on multi-level caching, solving the problem of data latency between cloud and on-premises
- Low-cost online erasure coding storage engine
- Support for single-replica storage, adapting to business needs for low data durability
- Client-side hot updates without service interruption during upgrades
- Performance optimizations, including metadata node migration, large directory page retrieval, data node memory pool usage, and metric grading
- Go mod used for project management
Version Link: https://github.com/cubefs/cubefs/releases/tag/v3.0.0
Architecture Adjustments
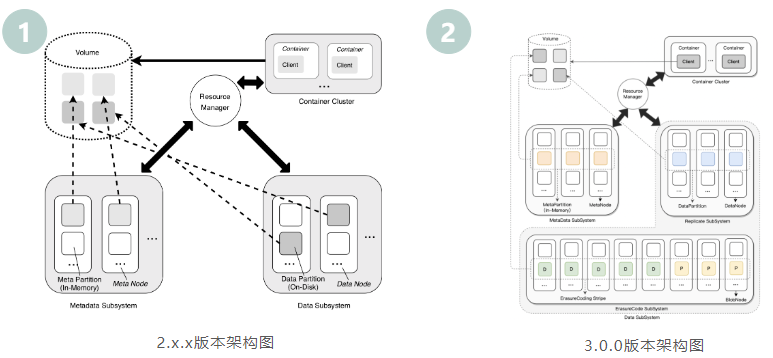
Version 3.0.0 adds an erasure coding storage engine with the ability to provide multiple copies and erasure coding at the storage layer; it is also compatible with previous versions and can smoothly upgrade to Version 3.0.0.
Feature Introduction
Hybrid Cloud Acceleration Based on Multi-Level Caching
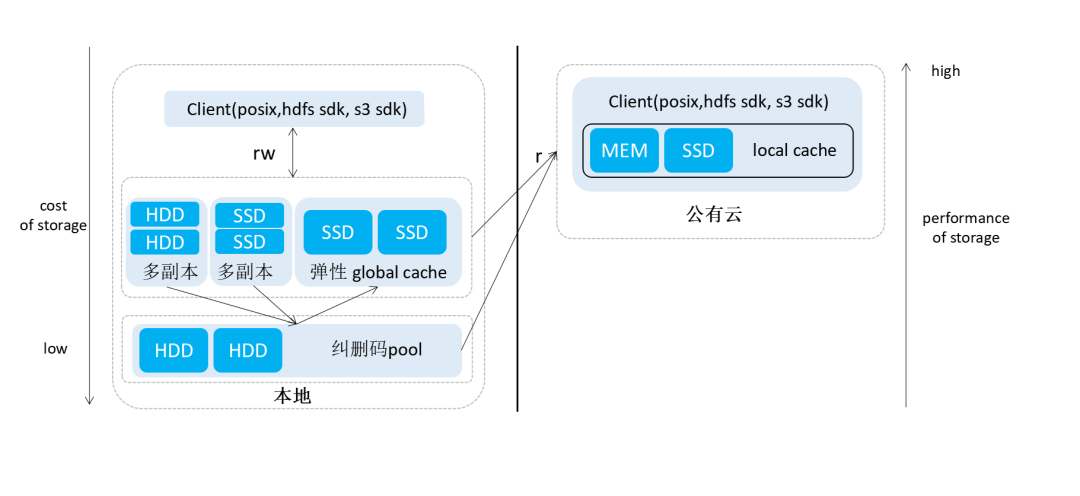
The storage system is based on automatic data hot/cold tiering, and users can flexibly configure volume policies to dynamically adapt to business cost and performance requirements, providing more possibilities for storage orchestration.
Erasure Coding
The erasure coding subsystem has the following advantages:
- Larger cluster capacity
- Higher durability with 12 nines
- Lower TCO, reducing redundancy from 3x to 1.33x or less
- Deployable in multiple availability zones
- Various erasure coding modes can be configured
- Online erasure coding can avoid data migration and save storage space
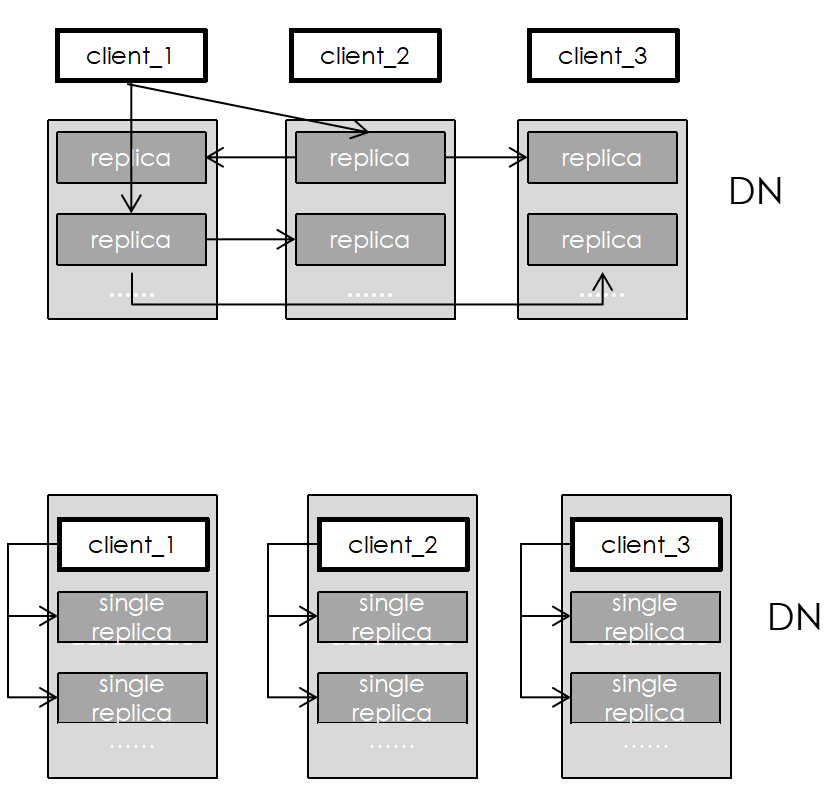
Single-replica
Single-replica is suitable for businesses with low reliability requirements, such as Spark remote shuffle.
Users can choose from Single-replica to three-replica storage, and the lower the number of copies, the lower the storage cost and write latency.
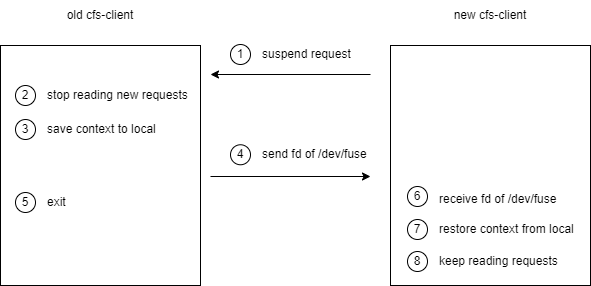
Client-Side Hot Updates
Client-side hot updates can ensure business continuity, especially for long tasks such as AI training or big data analysis, without worrying about service interruption caused by client upgrades.
Performance Optimizations
- Metadata node migration
By reducing system calls on the critical path of snapshot processing, the migration time for millions of inodes is reduced from hours to minutes.
- Large directory page retrieval
By implementing page retrieval and timeout retry mechanism, it solves the problem of large directory data volume per retrieval, network jitter, and frequent failures.
- DataNode memory pool usage
By improving the utilization of data buffer pools, CPU usage is reduced by nearly 40%.
- Metric grading
By implementing index grading strategy, the index data volume is reduced, and CPU usage is reduced by 30%.
Future Version Plans
Version roadmap can be found at: https://github.com/CubeFS/CubeFS/blob/master/ROADMAP.md
Preview of Version 3.1.0 updates:
- The erasure coding (blobstore) code repository is merged into CubeFS
- New QOS traffic control system
- Support for two copies
- Optimization of data migration algorithm to improve stability
In addition, we would like to thank all the community members who have contributed to the design and development of this version:
- Xiaochun HE,https://github.com/xiaochunhe
- Hongyan Wang,https://github.com/jadewang198510
- Tianjiong Zhang ,https://github.com/tianjiongzhang
- Shuoran Liu ,https://github.com/shuoranliu
- Chi He,https://github.com/bboyCH4
- Xiang Li ,https://github.com/lixiang
- Liang Chang ,https://github.com/leonrayang
- Xuewei Zeng,https://github.com/Victor1319
- Yong Sheng ,https://github.com/shyodx
- Zhengyi Zhu ,https://github.com/zhuzhengyi
- Xiaobo Yu,https://github.com/cessory
- Cloudstriff ,https://github.com/Cloudstriff
- Zongchao Hu ,https://github.com/JasonHu520
- Tianyue Peng ,https://github.com/pengtianyue025
- Slasher ,https://github.com/sejust
- Zhixiang Tang ,https://github.com/xiangcai1215