
CubeFS技术揭秘 | CubeFS助力大模型训练加速
01 导读
当OpenAI于2022年发布ChatGPT,人工智能进入了全新时代,大模型技术的出现引发了各行业的颠覆性创新,带来了应用体验的显著提升和新的商业化机会,同时也对云基础设施提出了新的挑战;存储作为云基础设施,本质是数据服务,是大模型技术栈的重要一环;大型模型时代,寻找适合的云存储解决方案显得尤为重要。
本文将结合CubeFS及OPPO自研AndesGPT,探讨大型模型时代的数据存储解决之道,助力企业决胜大模型时代。文章将从以下三个方面展开讨论:
- 大模型对数据存储的需求和挑战
- 基于CubeFS的大型模型存储解决方案
- CubeFS助力AndesGPT应用实践
02 大模型存储的需求及挑战
我们先梳理整个大模型全链路工作流,梳理大模型对存储的需求

大模型工作流可划分为三个阶段,从开始的数据归集存储及加工,到模型开发训练,最后到在线推理,各个环节都需与存储强交互,不同阶段对存储都有不同的需求及挑战。
1、数据存储及处理
这一阶段的存储诉求是大规模、高效统一。大模型依赖的数据量庞大,这些数据可能分布在不同的数据中心、不同的云,将这些数据归集到一起是大模型训练的前提。如何才能将数据高效的归集到一起呢?首先要有一套大容量、可扩展的存储平台,其次是平台能支持多个途径快速归集及不同数据源的数据导入,此外数据的加工处理,如清洗、标注、去重、增强等要求同一份数据集能在不同的数据处理平台间共享及互通。
2、模型开发与训练
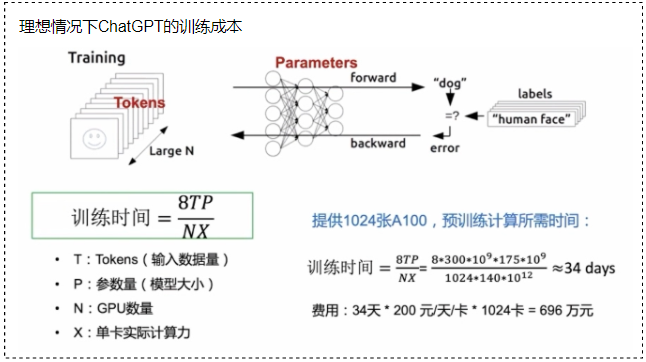
这一阶段存储诉求是GPU跑满零等待。大模型单次训练成本千万起,算力需求高、训练周期长,由于大模型参数量巨大(如GPT-3直接用170B规模的参数量,Google推出万亿稀疏switch transformer,Microsoft推出Turing-NLG, 都是千亿级别参数),往往都是数千卡GPU并行计算数月,存储并行IO能力及稳定性直接关系到大模型训练成本。
3、模型归档及线上推理
这一阶段存储诉求是秒级分发。模型归档验证通过后就需要快速分发部署到在线推理服务,从而产生业务价值。整个更新过程要求快速、同步,即所有的推理节点能在同一时间完成模型更新,避免出现各推理节点模型不一致、更新周期长影响业务的推理效果及用户体验,要做到秒级同步下发,就要求存储具备超大并发和高吞吐。
通过上述梳理,从整体上我们认为大模型对存储的挑战,主要是以下几点:
挑战一:大容量与高效数据互通
大模型的工作流依赖海量数据的快速归集、多渠道治理、数据在不同流通环节能共享及互通,要求存储支持海量数据规模的同时,能对不同生命周期、不同热度的数据做到统一存储,各种超大目录、海量小文件弹性元数据管理, 并支持多种协议的数据快速接入。
挑战二:强悍性能及超高稳定性
如何匹配强大的GPU算力,让GPU零等待,考验存储的并行IO能力。存储足够稳定、checkpoint能快速保存,中断后能快速恢复才能避免训练不被中断阻塞,存储强悍的性能及稳定性是降低大模型的训练成本的关键。
挑战三:快速线上部署能力
模型更新效率关系业务收益。如何快速、频繁、一致地将数GB级别的模型分发到线上,对存储并发IO、吞吐、流程简便性都有极高的要求。
大容量、高性能的数据存储服务能提升大模型海量数据的治理、训练、模型分发的效率,是助力企业决胜AI大模型的关键。接下来,我们从几个维度一起来看看基于CubeFS的大模型存储解决方案。
03 CubeFS大模型存储之道
CubeFS简介
CubeFS (github:https://github.com/cubefs) 是新一代云原生开源存储产品,广泛应用于机器学习、容器平台、数据库、中间件等多种场景,托管于云原生计算基金会CNCF孵化阶段产品,具备以下特点:
- 多协议互通:提供S3、POSIX、HDFS等多种访问协议,协议间数据互通
- 高扩展性:元数据可轻松水平扩展,单集群支持EB级存储规模;
- 缓存加速:提供多级缓存加速能力,为热点数据提供更低访问时延;
- 云原生支持:基于CSI插件对接Kubernetes,同时方便在混合云环境快速部署;

海量数据管理
弹性元数据管理
现阶段的语言大模型以小文本为主,文件大小在字节级或者KB级,规模可达数百亿,这种海量小文件大幅增加元数据管理的复杂度,此外文件越小,元数据操作的耗时占比就会越高,在千万级超大目录,热点目录等各种复杂场景下,要保障小文件大规模存储及IO能力,做好元数据的管理是关键,先回顾一下常见分布式存储元数据管理的主流方案。
单机静态子树管理
整个namespace元数据托管给单机metanode,单机全量持久化集群元数据,优势在于访问延迟比较低,缺点就是扩展性受限,不支持横向扩展,受单节点资源限制,影响集群支持的文件数量和吞吐量。例如典型的HDFS、CephFS单MDS模式,单集群只能支持10-20亿级规模的文件数。
基于分布式KV引擎
将元数据存储到分布式KV引擎。将层级化的元数据转化成扁平的数据结构存储到KV数据库,再构建一层文件语义的网关对上层输出虚拟的目录层次结构,大部分对象存储都是采用类似方案。
由于原生的AI框架大多是基于标准的POSIX文件语义来操作存储,这种架构下,如rename、list等元数据操作会涉及多个KV的访问,元数据访问性能会很差,因此还需构建元数据加速缓存来解决部分性能问题。这种架构虽然能有效解决扩展性问题,但引入三方系统,避免不了额外的运营成本,同时元数据加速缓存的性能、数据一致性也会影响集群的稳定性。

CubeFS弹性元数据管理
弹性元数据管理需要解决的关键问题是将庞大的元数据进行拆分,实现横向可扩展,由多个元数据节点共同存储和均衡访问负载。
CubeFS的策略将元数据进行分区(meta partition,简称mp),每个mp负责维护一段range范围的元数据,如mp1、mp2.....mpx。mp维护文件的dentry及inode信息,并在内存中构建高性能Btree查询索引,通过raft机制保证多个副本间数据的强一致,并定期快照到本地磁盘和 Raft的wal日志保证高可靠。
最后一个mp 的range没有上限并且支持分裂,当最后一个 mp 所在 MetaNode 节点内存使用率达到一个阈值,会分裂成2个mp,新的mp 会根据内存权重分配到可用内存更多的 MetaNode上,以此完成元数据的扩展,整个过程无需迁移任务数据,对业务无感。

CubeFS元数据管理视图
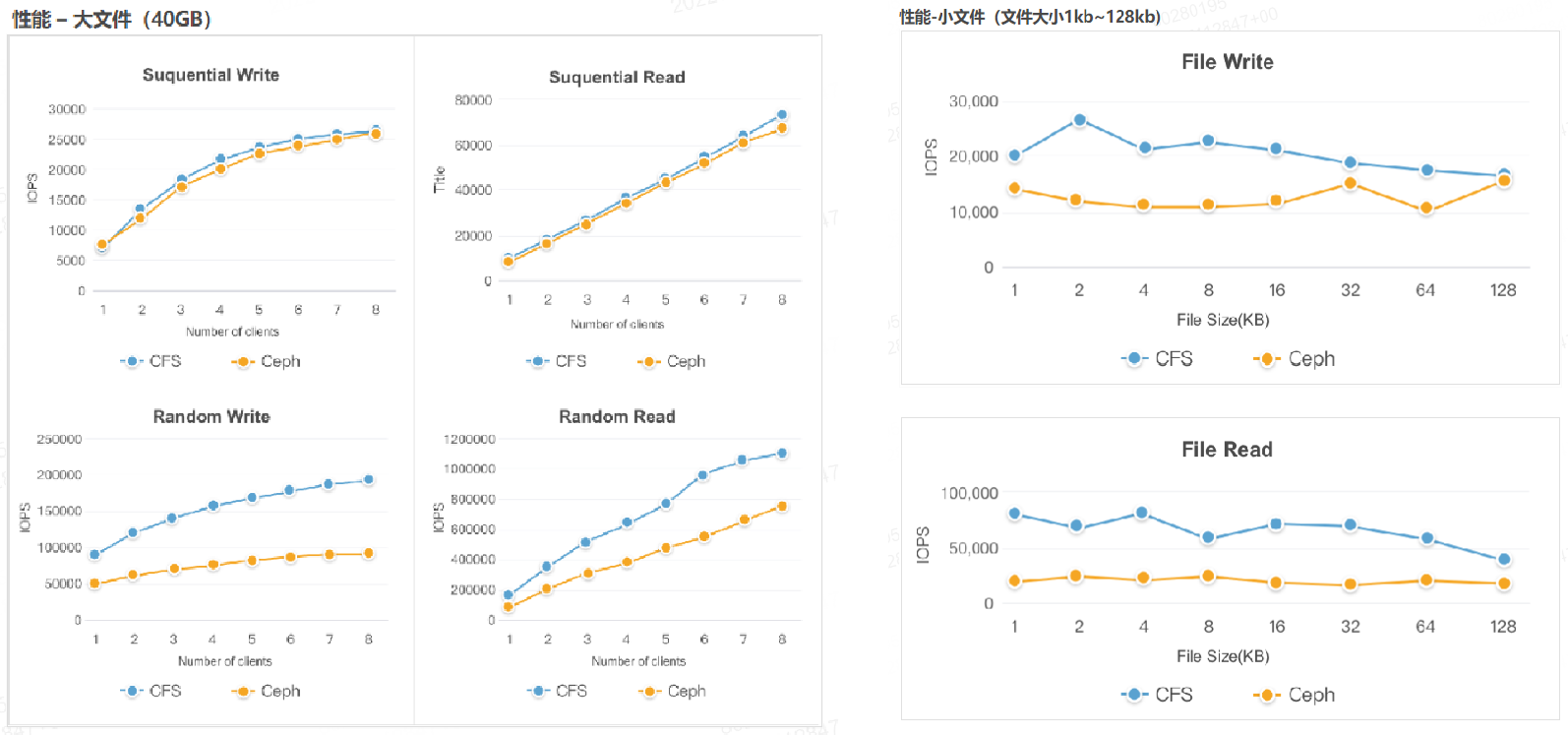
CubeFS元数据支持百万级QPS,可满足海量小文件的大模型训练高IOPS需求。下图是CubeFS与开源CephFS在大文件、小文件场景的IOPS性能对比,可以看到CubeFS KB小文件读写性能明显优化CephFS, 这得益于CubeFS高效的元数据管理能力。
统一分层存储底座
大模型数据量庞大,需要存储大量的原始语料集及模型参数,随着大模型的不断发展,数据类型也越来也多样化,从最初的文本模型扩展到音频,视频,图片等多种类型,业务存在不同数据类型、不同生命周期、不同热度的数据统一管理的诉求。
CubeFS支持两种存储引擎,多规格副本存储及低成本纠删码存储。副本存储可存储业务经常访问的热数据,譬如模型当前训练数据集,同时支持1、2、3副本多规格存储卷,提供更高的访问性能。低成本纠删码存储,不仅提供了在线EC能力,而且支持多种编码模式、跨可用区部署,可为业务提供更低成本、更安全可靠的冷数据管理能力。此外CubeFS还提供了基于生命周期的多种数据自动降冷策略,数据可基于热度可以在不同的存储引擎之间灵活的自动迁移,企业无需关心数据治理难题,就能最小化数据的存储成本。

数据访问互通
纵观大模型整个工作流,每个阶段数据都在流动,从预处理各个环节,到后期的模型镜像打包、分发,数据会经过在不同的处理平台,数据如何在这些平台之间高效的流动呢?核心关键在于存储对多协议接入的支持,支持多种访问方式,不同的访问方式之间数据共享,数据只存储一份。

CubeFS通过一套系统做到完美融合,兼容主流的POSIX文件存储、大数据HDFS、对象存储S3协议,且多协议之间共享一套元数据及数据,用户可以直接通过 S3 协议访问通过文件POSIX协议写入的数据,反之亦然,无需数据拷贝就能轻松实现数据复用,助力数据在大模型各流程无缝衔接,大幅提高数据的流动效率。
并行训练加速
大模型千卡GPU并行训练时,如何保证存储并行IO能力、高效的数据读取?高并发给远端存储带来巨大的IO压力,如何保障远端存储的稳定性,从而保障大模型的稳定输出?接下来,我们结合大模型训练过程中的IO特点来一起探讨解决方案。
大模型IO特点

上图是大模型分布式训练框架下的训练过程,整个过程对同一批数据集反复读取,多次计算迭代,它具有以下IO特点:
1)反复读取同一批数据集。每轮epoch都会读取同一数据集中的每一条数据,且仅读一次;
2)同一GPU节点每轮epoch读取的数据都是随机的。随机shuffle降数据集列表打散,防止模型过拟合, 图示GPU0两轮epoch处理的数据range是随机的。
3)训练过程中定期写入checkpoint用于训练中断后下次从当前的epoch恢复,整个checkpoint写入过程训练是阻塞的。
结合大模型训练IO特点,通过在算力节点和数据中心之间构建大规模分布式数据缓存加速,能大幅提升加速训练并行IO吞吐,同时分担远端存储的IO压力,提升整个系统稳定性。
多级数据缓存

CubeFS支持两级缓存加速,全量或者部分缓存训练数据,每轮epoch数据大部分都能从本地或者缓存节点读取, 大幅提升IO效率。
一级本地缓存
计算端缓存,利用计算节点本地空闲的内存及磁盘资源,部署加速服务,缓存业务最近访问的数据。一级缓存包括基于内存的元数据缓存及基于磁盘/内存的数据缓存两个部分,其中元数据缓存又包括inode缓存、dentry缓存,可大幅降低FUSE在Lookup,Open读文件时的元数据查询延时开销,数据缓存主要缓存文件数据块。一级缓存性能好,受限于本地节点存储容量,可实现千万级元数据,TB级数据的局部缓存加速。
二级分布式缓存
多AZ混合部署
在算力集群所在AZ或者靠近训练作业的节点附近部署缓存节点,多个AZ的缓存节点组成全局的大规模分布式缓存,可以轻松做到一份Dataset,多地训练,在CubeFS上保存一份数据,可以通过缓存的机制把数据带到任何计算相关的区域。
区域感知&弹性副本
在数据管理上,L2Cache将一个数据文件的的多个数据块的缓存到不同的CacheNode节点,如图中8M.file文件的块A和块B缓存的不同的Node。同时单个数据块支持弹性副本和区域感知,弹性副本可以让数据块在缓存中上保存多个副本,区域感知可确保每个AZ的缓存节点都有数据块,如图例中的块B同时在两个AZ中均有缓存副本,这种方式,可以有效避免多个AZ同时读取一个数据块时,出现跨AZ访问缓存的情况,相对于L1Cache, L2Cache的访问需要经过网络, 但是容量更大,吞吐能力更强,可完全动态扩缩容,L2Cache非常适合数百TB~PB级别的大模型训练的数据加速。

多种缓存策略
在缓存淘汰策略上,传统的LRU淘汰算法并不适合大模型的场景,和以往一些业务场景随机的热点访问不同,大模型训练的数据读取是非常有规律的,整个数据集被全部读取一遍后,才会访问下一轮。当缓存空间不足,LRU会率先把较早访问的数据淘汰掉, 由于大模型数据量庞大,当缓存的空间大小小于训练的数据集大小,就会存在缓存被打穿的情况,表现为上一轮epoch后半阶段会把前半阶段缓存的数据淘汰掉,而前半阶段缓存的数据恰好又是下一轮迭代需要用到的数据,如此循环导致后面的访问都不会再命中缓存,从而严重影响大模型缓存加速的效果,甚至带来负面影响。

针对大模型这种读取特性,CubeFS提供了两种缓存策略,LRU和TTL缓存。TTL是基于过期时间数据淘汰,加速层最大化缓存数据,数据未达TTL之前,会一直在缓存中,确保多轮迭代的命中效果,两种策略业务可结合实际场景合理配置。
首轮epoch加速
除了训练作业过程中动态缓存数据以外,CubeFS还针对大数据量的训练作业提供了数据预热的功能,加速训练首轮迭代。不同于动态缓存首轮epoch缓存是空的,数据需要从远端加载,在第二轮epoch时才有加速效果,数据预热通过提前缓存数据,首轮迭代就能加速,解决第一个epoch速度极慢的问题。
加速效果对比

多级缓存加速效果对比
小结
CubeFS两级缓存加速+数据预读的组合加速方案,能大幅提升数据的加载速度,可为训练框架提供数百GB~TB/S的吞吐带宽,满足大模型千卡GPU并行训练的IO带宽需求。同时L1Cache 和L2Cache在设计上可以插拔,业务可以按需部署,满足不同场景的业务需求。对于一些语言类的模型,数据量在数TB级别的规模,字节级的小IO读,对延时要求很高,适合用L1Cache;对于一些图片类的模型,数据量通常比较大,算力节点本地空间有限,将数据缓存到基于SSD高性能盘的L2Cache会更合适。
快速checkpoint写入
前面大模型训练流程得知,大模型的checkpoint技术能有效的为大模型提供训练中断后的原地恢复训练的能力, 但整个checkpoint写入过程会阻塞框架的训练作业,从而导致GPU空闲, 此外checkpoint过程是多个训练节点同时写,恢复时同时读,且写入数据量大,单节点数GB级别,因此对远端存储的写入吞吐及延时要求极高。
GDS
CubeFS采用了GPU Direct Storage技术(简称GDS, 此技术在OPPO内部业务上正在试用),通过直接内存访问(Direct Memory Access,DMA)方式,将GPU的显存直接关联CubeFS远端存储,数据读写绕过CPU以加速数据传输过程。通过使用GPU Direct Storage,GPU可以直接从远端存储设备中读写数据, 这种直传的方式有效减少数据的拷贝次数,大幅降低了数据传输的延迟和开销,能为上层AI框架提供稳定的写入带宽吞吐,从而提高大模型checkpoint的效率和性能。

RDMA
CubeFS支持客户端到后端数据服务节点datanode的RDMA通讯技术(此技术在OPPO内部业务上正在试用),进一步降低框架checkpoint数据写到后端的延时。RDMA(Remote Direct Memory Access)技术实现了在网络传输过程中两个节点之间数据缓冲区数据的直接传递,在本节点可以直接将数据通过网络传送到远程节点的内存中,绕过操作系统内的多次内存拷贝。相比于传统的网络传输,RDMA无需操作系统和TCP/IP协议的介入,不需要远程节点CPU等资源的介入,可以轻易的实现超低延时的数据处理、超高吞吐量传输。


CubeFS基于GDS + RDMA的快速checkpoint写入技术,能提供最低的写入延时及最高的写入吞吐,大幅减少框架写入过程中的训练阻塞时间,进一步提高GPU利用率,有效保障大模型训练故障中断后能快速恢复。
模型快速分发
训练产出的模型文件经过打包、压缩后会持久化到镜像仓库,各节点推理服务检测到模型有更新后,从镜像仓库拉取模型镜像到本地存储,经过解压和数据校验后完成模型的更新。在这个典型的模型更新流程中,由于推理服务节点规模大,多个节点并行同步更新,瞬间产生极大IO读带宽,底层镜像存储仓库IO打满,导致模型更新周期长、更新节奏不可控、各节点更新不同步等问题。

基于CubeFS分布式高性能缓存构建的模型分发服务能轻松解决这个问题。 首先CubeFS分布式缓存提供的预加载及区域感知能力,可以让用户主动将新的模型文件缓存到离推理服务最近的节点, 模型完全缓存后在通知推理服务更新,缓存极高的读命中率可分担镜像仓库大量的读带宽;其次CubeFS弹性副本能力,支持将模型文件缓存N个副本,进一步打散模型文件的数据块,均衡访问压力,实现模型的快速分发。
04 CubeFS助力AndesGPT
自建云统一存储
整个OPPO大规模机器学习平台,底层基于CubeFS的统一数据湖存储底座,通过整合多个平台的GPU算力,构建成集AI训练、优化、推理为一体的大型统一的分布式训练作业平台,支撑公司AndesGPT、小布智能助手、端云协同模型推理等多个业务。基于CubeFS大模型存储支持千亿级参数的AI大模型实时训练以及更安全的用户隐私保护,促进OPPO AI能力进一步向自适应AI、生成式AI演进。

混合云算力加速
CubeFS多级缓存混合云算力加速技术,支撑OPPO AI训练平台多云算力的动态调度,实现云上、云下算力用户无感弹性切换,自建云维护常态化的算力水位,将突发算力动态将任务调度到公有云,既能轻松实现算力无限扩展,又能最小化运营成本,每年为公司节省数亿元成本。通过测试RESNET18、RESNET50(非IO瓶颈)、AlexNet 模型在OPPO私有云、公有云开启训练加速后性能测试对比,如下图所示:

05 后续规划
CubeFS后续将持续优化对大模型训练加速场景的支持,更好的服务于AI应用,以下是CubeFS的For大模型的一些关键特性roadmap,部分正在研发中:
- 一级分布式缓存。 优化一级本地缓存,整合计算节点的空闲资源,构建一级全局分布式缓存,并支持多种缓存介质(内存、磁盘)及灵活的缓存控制策略, 保障缓存数据一致性, 实现加速用户无感知。
- GDS+全链路RDMA。从当前仅支持client->datanode数据IO路径RDMA,扩展到client、metanode、datanode及副本节点间全链路支持RDMA,进一步降低元数据读写、多副本写入的延时, 提升系统吞吐。
- 提供内核客户端。提供原生的CubeFS内核客户端,相对于现有用户态客户端,可大幅减少上下文切换开销,从而提供更高的文件读写操作性能;内核客户端会for AI场景提供更多定制优化特性,譬如与存储服务端结合,通过提供更大的IO block来提高吞吐等。
- 边云数据分层。 继续完善从边到云的智能分层存储能力,客户端写缓存(数据写本地)->服务端多副本层(SSD/HDD)->服务端纠删码层(HDD)->服务端归档存储层(磁带), 数据可以在各个存储层之间的流动,并基于生命周期策略数据冷热自动分层,持续优化大模型存储成本。
06 总结
面向大模型场景,CubeFS致力于提供高性能AI存储解决方案,后续将继续在训练加速、模型快速分发等方向上深度演进,进一步构建大模型多样化存储能力,助力企业决胜大模型。