
与CubeFS共创未来:BIGO的实践与思考
背景
随着BIGO机器学习平台模型和数据量的增长,对底层依赖的文件系统提出了更多的需求,如多租户、高并发、多机房高可用、高性能、云原生等特性
技术选型
经过技术选型,多角度对比之后觉得CubeFS有很多特性适合我们机器学习平台的应用场景:
- 租户隔离:CubeFS可以通过为不同业务线创建不同volume来做租户隔离。
- 高并发:我们的模型在训练时,会有上万客户端挂载同一个实例进行读写,对并发访问要求比较高,CubeFS通过分片的方式,将请求分散到多个元数据节点,适合高并发访问场景。
- 海量小文件:我们存储的基本都是小文件,CubeFS通过将小文件内容聚合在一个文件中优化小文件的存储;同时,CubeFS具有可动态扩展的元数据特性,不会出现单元数据节点内存瓶颈。
从测试到生产
我们在2022年11月份开始对CubeFS进行系统性测试,从测试结果看CubeFS无论是在功能上还是性能上都能较好的满足我们的使用需求。所以,我们决定用CubeFS来搭建生产环境的文件存储服务,并开始一段时间长稳测试。
这个期间我们也做了一些BUG修复和功能优化,提升系统的稳定性和运维效率,测试过程中没有遇到严重问题,特别是服务端或客户端异常导致应用卡住问题。测试结果得到了用户的认可
最终在2023年3月份,我们开始将生产环境的任务和数据向CubeFS集群迁移。目前我们的机器学习平台通过在容器中挂载CubeFS实现共享访问,在模型训练期间读写配置文件和应用日志。
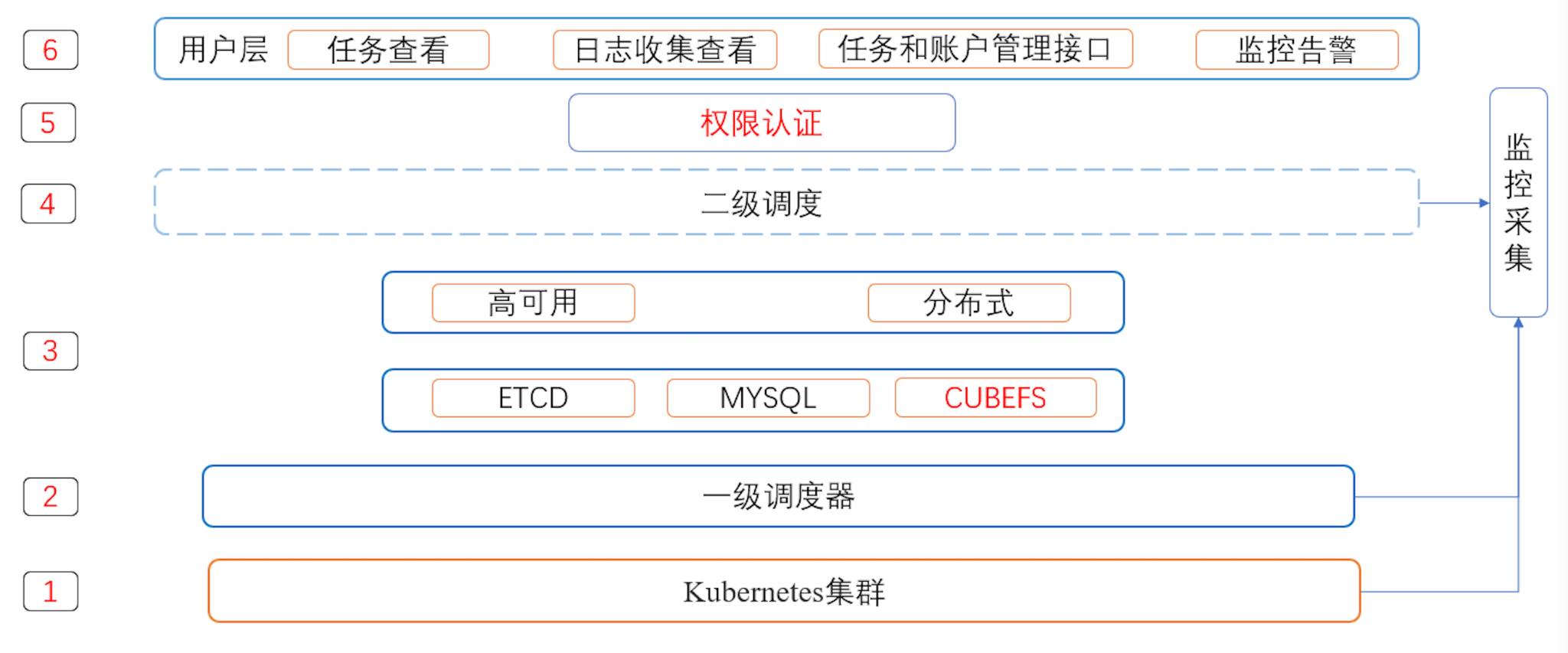
在BIGO的实践
下面介绍一下我们在CubeFS实践中的一些工作。
稳定性优化
在测试过程中,我们修复了多个问题以提高系统稳定性,新增一些命令来提高运维效率,并增加多个监控辅助问题定位。相关的pr都放在下面的issue中。
[Bug]: datanode shutdown may cause client failed #issue-1794
[Bug]: fix some bug to improve cluster stability #issue-1786
[Feature]: add more info to cli/fsck cmd #issue-1793
[Feature]: add some metrics #issue-1785
新增审计日志功能
在生产环境中,需要审计日志功能来查看客户操作是否合规,同时也能辅助分析客户操作逻辑。与社区沟通后,确认了社区会将审计日志功能放到客户端收集并且得等到release-3.2.1版本中才发布,所以我们决定先在内部版本中开发审计日志功能。
由于客户端操作命令在fuse层会被拆分为多个操作发送给MetaNode,因此将审计日志收集到服务端首先需要获取的信息是请求的全路径。在与CubeFS社区沟通后,我们了解到可以在fuse client端,利用nodeCache结构体反向推出父目录节点,直到根目录,进而可以拼装成全路径。另一个需要获取的信息是用户信息,通过user.LookupId请求将fuse.request里面uid信息反向解析得到用户信息,并将用uid与户信息缓存在客户端,减少请求调用。最终将审计日志相关信息发送到MetaNode节点,并带上操作命令信息,标记MetaNode相关操作来自哪个命令。
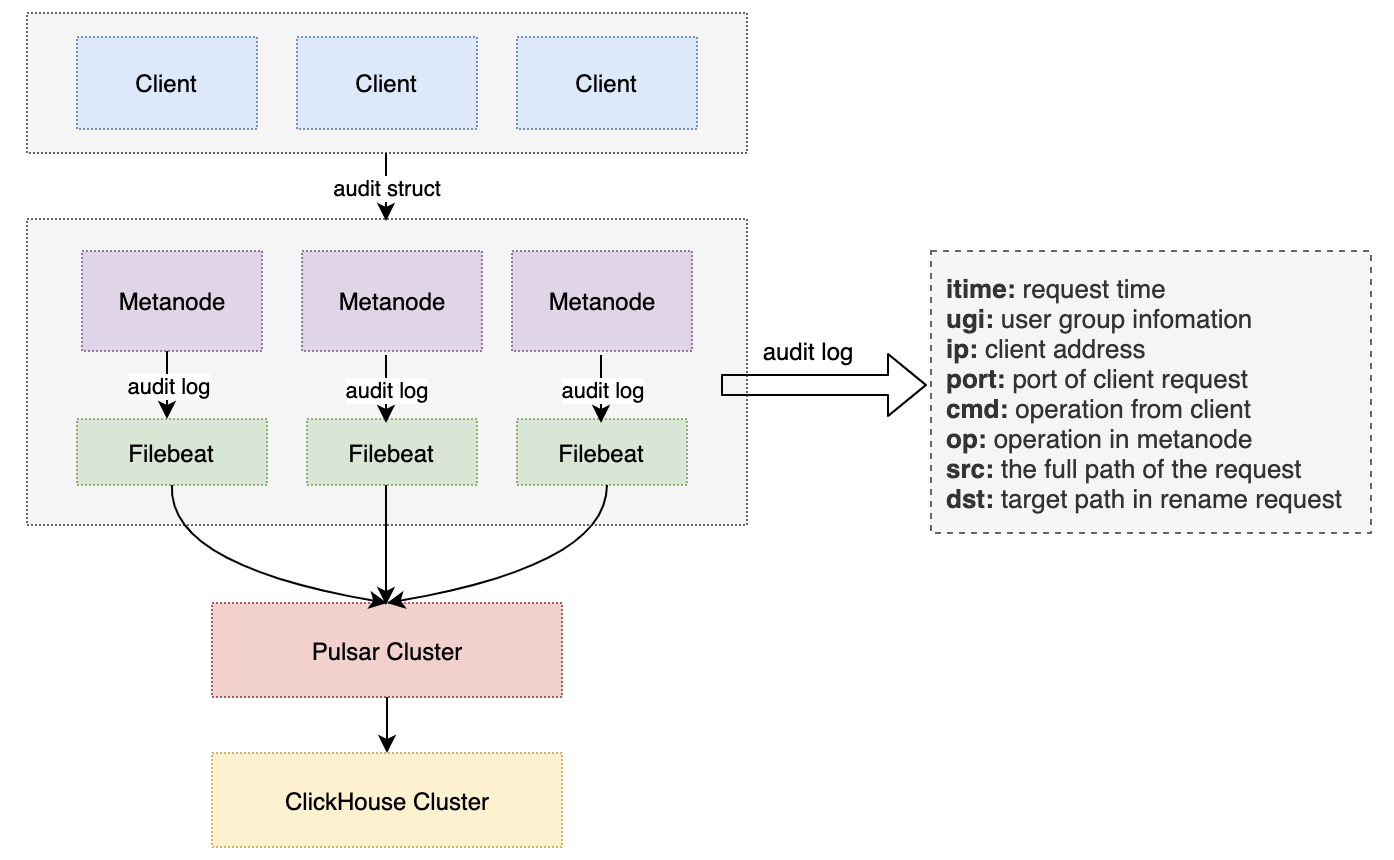
当MetaNode写完审计日志后可以被Filebeat收集并写入Pulsar集群,最终写入到ClickHouse保存,这样可以通过SQL语句进行多维度查询。
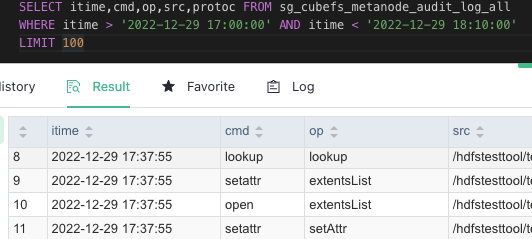
因为社区代码已有审计日志相关功能,我们就没有将相关代码提交到社区,该功能已经在内部上线到生产环境。
新增客户端检测超时功能和超时报错功能
根据我们用户以往使用其他文件服务的一些经历,他们希望我们可以提供一个快速检测请求超时的功能和服务端异常导致请求阻塞之后能超时返回错误的功能。为了能快速准确地识别请求是否超时,如果给客户端的每个操作都安排一个协程去监控的话,就需要开启大量的协程,造成资源的浪费。因此,我们实现了一个只用一个协程去检测所有操作超时的算法,并且可以知道哪个进程哪个操作出现超时,方便快速排查超时原因。
算法大致思路是,假设超时时间等于一个时间窗口大小,若在当前时间窗口(记为窗口a)客户端某个操作开始了,我们会在窗口a对应的计数器(记为计数器a)做+1处理,后续只要该操作在超时时间内完成,则对计数器a做-1处理。这样一来,当窗口a结束之后,计数器a在等待多1个时间窗口后,计数器a所记录的值即为超时的操作数量。在该算法中,我们给定3个计数器,让其轮流工作,以保证统计操作超时的准确性。
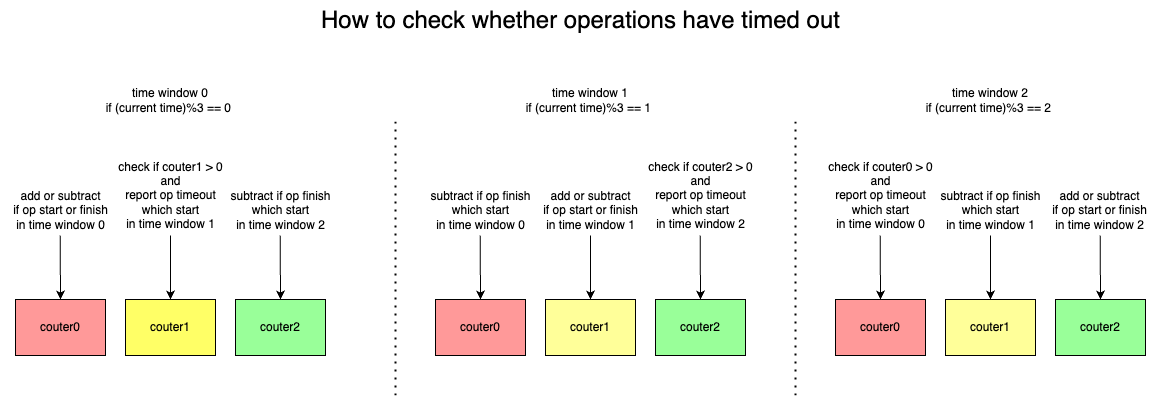
为了能实现请求超时之后返回错误给客户端,我们在fuse层增加了超时检测,当某个请求的处理时间超过了一定阈值,则会给客户端返回超时出错。我们通过配置来控制这个功能只针对部分用户进行使用。相关pr:
[Enhancement] add request monitor for client #pr-1863
[Enhancemant] Support fuse request timeout, add client metrics #pr-1674
新增集群识别功能
在一次升级CubeFS集群过程中,我们错误的使用了集群B的配置来启动集群A的MetaNode,该MetaNode能正常启动,但是加入到了集群B中,发现该问题后我们快速的将该节点从集群B下线并重新上线到集群A。如果集群A有两个MetaNode被错误的加入到集群B,那么对集群A可能会有部分metapartition缺失两副本,造成严重后果。
这个问题的主要原因是MetaNode和DataNode在启动的过程没有检测节点自身是否已经属于某一个集群。因此,我们开发了集群识别功能,通过命令生成集群唯一ID并持久化在Master的rocksdb中,在MetaNode和DataNode第一次启动时会从Master获取该ID持久化到数据目录,后面重启都会与Master记录的ID进行检查,确保不会加入到其他集群。同时,为了兼容旧集群,我们增加了开关来控制该集群ID检测功能。如果旧集群要升级该功能,只需要将生成的持久化文件拷贝到集群节点上数据目录,重启节点即可。相关pr:
Feature: add ClusterUUID for mn/dn to identify a cluster upon restart #pr-1862
新增自动补充数据副本功能
在CubeFS中,DataNode用数据分片存储数据,为了数据的可靠性,数据分片以三副本方式保存在不同DataNode的磁盘上。但由于磁盘可能损坏,造成副本减少,当三个副本都损坏后,就会造成数据丢失。因此除了及时发现数据副本缺失外,还需要及时补充数据副本。一般运维的介入会有延迟和误操作的风险,因此我们开发了自动补充数据副本功能,当检测到数据副本丢失,会自动调度到适合的节点上补充数据副本,通过自动化修复的方式减少人工运维成本。相关pr:
[Enhancement] automatically add data replica for data partitions which lack replica #pr-1676
新增数据节点自动下线和磁盘自动下线功能
当数据节点进程由于某种原因退出时,会导致多个datapartition缺失一个副本,需要尽快将该节点下线,减少数据丢失风险。为了减少人工运维的成本,我们开发了数据节点自动下线功能,当DataNode进程退出后,Master通过心跳检测发现该节点异常,会自动将该节点从资源节点中下线,进而分批调度下线该节点的datapartition至其他节点上,并控制下线速度保证不对集群性能造成太大影响。同时,该功能也包含了磁盘自动下线功能,当有磁盘损坏时,会上报到Master,由Master自动调度将该磁盘上面的datapartition迁移到其他节点上。
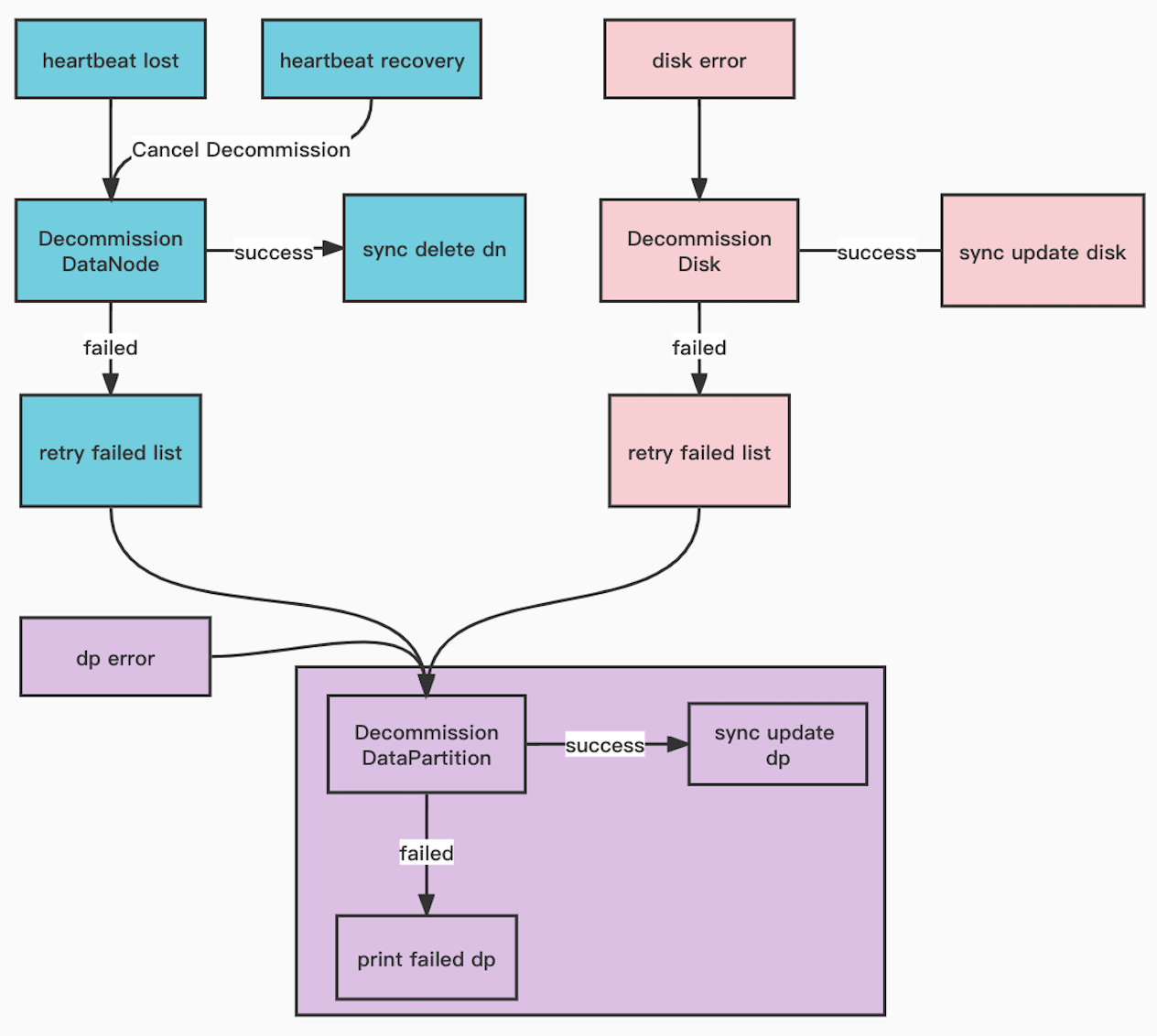
相关pr:
[Feature] Decommission datapartitions, disks and datanodes automatically #pr-1709
元数据节点启动加速
元数据节点是将元数据都加载到内存中,当集群中文件数较多时,重启元数据节点需要较长时间,特别是升级版本时,需要重启整个集群中所有的元数据节点,时间会很长。通过查看代码发现MetaNode在启动时,每一个metapartition都是串行加载元数据文件,而且每个文件之间没有互相依赖关系,则可以通过并发加载多个文件的方式来缩短启动时间,优化后MetaNode启动时间可以减少至原来的50%左右。后续可以用多个协程加载同一个元数据文件作为进一步优化。相关pr:
[Enhancement] speed up metanode startup #pr-1643
新增文件统计功能
为了了解每个volume的业务特性和负载情况以及方便统计volume使用成本,我们需要知道每个volume的文件使用情况,比如该volume是使用大文件比较多还是小文件比较多,文件大小的占比情况。我们通过解析每个metapartition的快照文件,进行volume分类,并控制统计频率和解析文件的速率,减小该功能对整个集群的性能影响,最终将数据上报到监控系统,这样就可以在监控页面查看每个volume的文件分布情况。下图显示某个volume的文件分布情况。
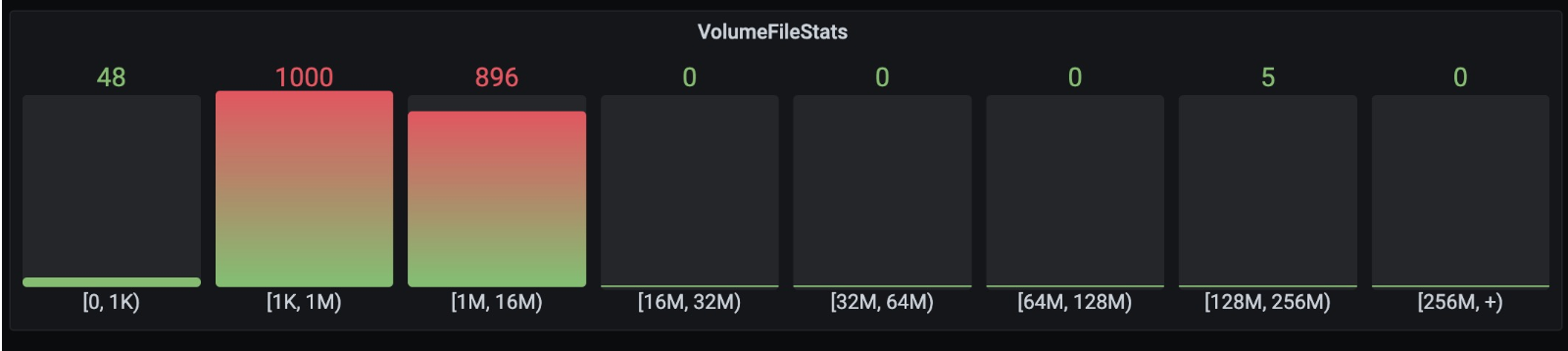
相关pr:
[Feature] add file statistics function #1739
未来展望
目前我们的生产集群上线时间不长,主要工作还是围绕系统稳定性和自动化运维进行开展,提供的主要服务也是文件存储相关的功能。未来工作会继续在系统稳定性和安全性等方面进一步开展工作,保障用户使用体验和数据安全;放开对象存储功能,为有需要的用户提供对象存储服务。
总结&感谢
以上就是我们CubeFS实践过程中的一些工作,后期我们也会多与社区合作,尝试做更多功能开发,争取为CubeFS发展社区做更多贡献。在这里也要感谢CubeFS社区和OPPO团队的同学对我们在使用CubeFS过程中的大力支持,帮助我们快速熟悉CubeFS,及时解答我们的一些问题。